Imagine running a daily newsletter like Morning Brew or The Hustle without hiring a single writer. This article reveals how to create a fully automated AI-powered newsletter that sources, writes, and curates content on its own. This approach can be applied to any industry or niche, offering a scalable way to build a media business without a traditional content team. If you want to tap into AI automation for publishing, this guide will walk you through the entire process from scraping AI news to generating the complete newsletter.
Before diving into the details, consider joining our AI Automation Community. There, you can get the complete n8n automation template for this newsletter system and access resources to build your own AI-powered workflows.
How to Automate a Newsletter Like a Human Writer
The system is designed to mimic the workflow of a human newsletter writer but without manual effort. It splits into two main streams:
- AI Data Ingestion: Automatically pulls content from various online sources.
- Newsletter Generation: Analyzes the collected content, selects top stories, writes the newsletter, and formats it for publishing.
Content is sourced from popular AI company blogs, Google News API, Hacker News, Reddit subreddits, Twitter, and other AI-related news outlets. The text content is cleaned and validated to ensure relevance before being stored in a centralized data lake hosted on Cloudflare’s S3-compatible storage.
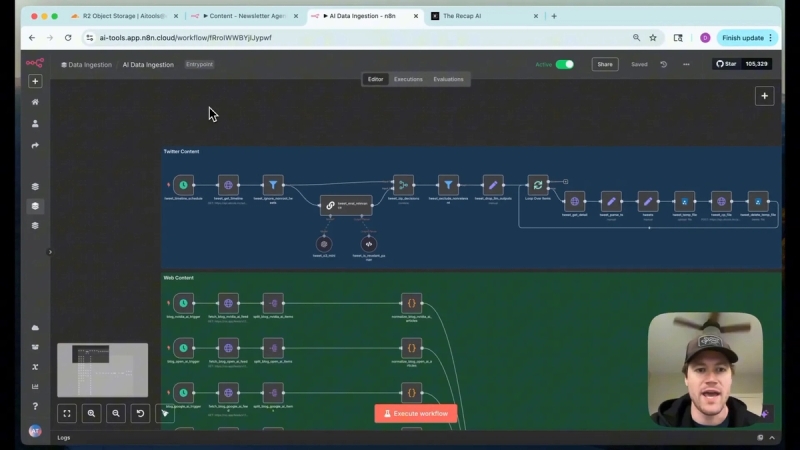
Building the News Scraping Pipeline
The scraping pipeline is the backbone that gathers all relevant news stories daily. It uses scheduled triggers to fetch content from multiple feeds:
- Official blogs from AI companies like OpenAI, Google AI, Anthropic
- Reddit subreddits dedicated to AI discussions
- Hacker News and Google News feeds focused on AI
- Twitter's “For You” page, curated to surface top AI news
- Other newsletters, including the newsletter itself as a sanity check
Once scraped, the data is pushed to the data lake, organized by date, where each story is saved as a markdown file. This structured storage allows easy retrieval and processing later.
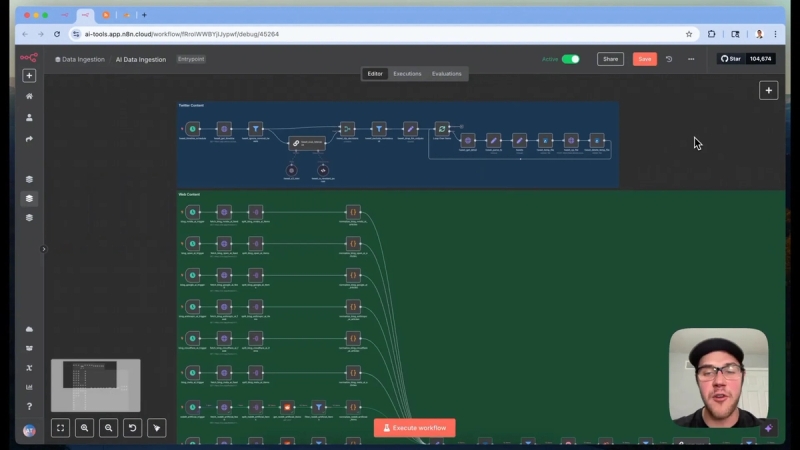
Example: Automating Reddit Content Scraping
Reddit posts are fetched every 3 hours via a configured RSS feed using RSS.app. This service generates JSON feeds of subreddit posts, which are then split into individual items. Additional metadata for each post is retrieved to capture full text and extra information like publication dates and sources.
A filter excludes irrelevant posts such as text-only Reddit posts, Twitter or YouTube links, GitHub repositories, or Reddit-hosted images/videos. The focus is on external links pointing to original AI news articles or blog posts.
Metadata is normalized to a consistent format for all sources, which simplifies later processing and reduces duplication.
Efficient Scraping with Deduplication
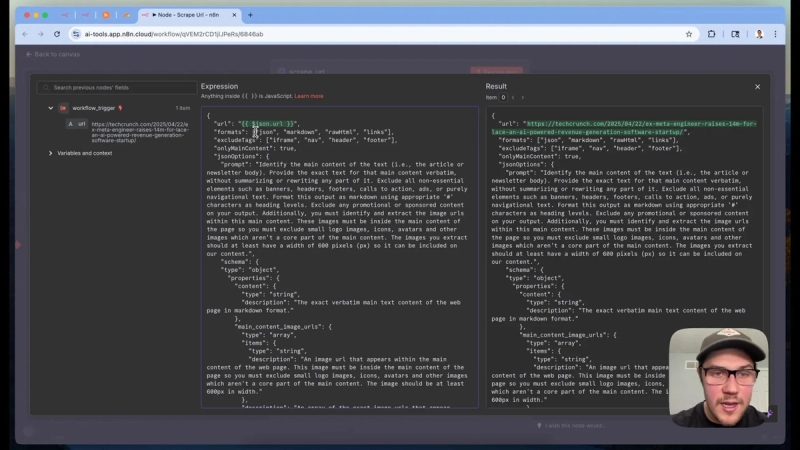
Before scraping a URL, the system checks if the article already exists in the data lake to avoid redundant scraping. This saves API credits and speeds up the process. If the article is new, it proceeds to scrape the full content using a service called Firecrawl.
Firecrawl extracts the main article content from web pages in clean markdown format, ignoring extraneous elements like headers, authorship details, or sidebars. This focused content is ideal for AI prompt processing.
Filtering and Validating Content
Not every scraped article is relevant. The pipeline uses an AI evaluation step to filter out noisy or off-topic articles. For example, political stories or AI-adjacent content that doesn't fit the newsletter's focus are excluded.
To improve quality, the AI prompt can be fine-tuned with examples of good and bad stories, helping ensure only the best candidates make it into the data lake.
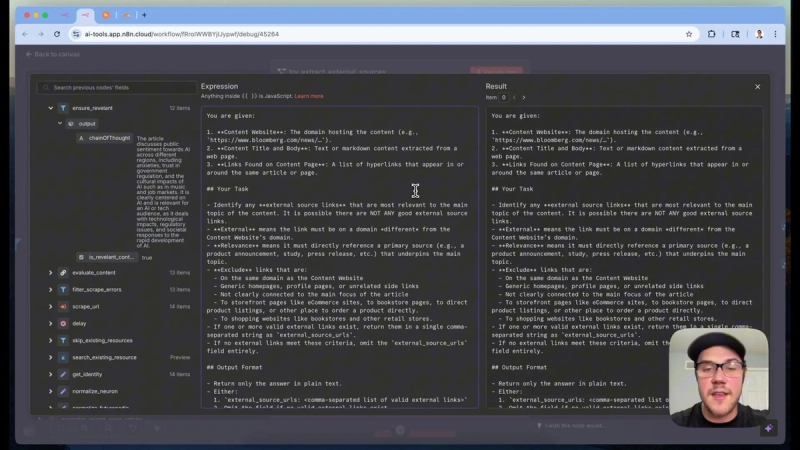
Extracting Primary Sources
Often, news articles link to primary sources like official PDFs or company blog posts. The system scans scraped articles to detect these outbound links and schedules additional scraping of those sources. This deepens the context and accuracy of the newsletter content.
Loading and Preparing Content for Newsletter Generation
With the data lake populated, the next step is to retrieve all relevant stories for the newsletter date. The system searches the data lake by date and downloads markdown files for processing.
To avoid repeating stories, the previous newsletter content is provided as input. This helps the AI exclude stories already covered recently, preventing duplication in consecutive editions.
Combining Data for AI Prompting
All downloaded markdown files are processed to extract clean text content and metadata. The stories are then aggregated into a single field formatted for language model input, using clear delimiters around each story to guide the AI.
Twitter content is loaded similarly but saved as JSON files with tweet IDs. Both news articles and tweets are combined to provide a comprehensive pool of content for the newsletter.
Selecting Top Stories with AI
The AI receives the aggregated scraped content and the previous newsletter's stories as input. It is prompted to:
- Group related stories
- Identify the most important and interesting 3-4 stories for the audience
- Provide summaries and metadata for each selected story
The output is a structured JSON array containing titles, summaries, and identifiers for each top story. A human editor reviews these selections via Slack and can approve or request replacements. This human-in-the-loop step ensures quality control.

Crafting the Newsletter Subject Line
Once top stories are approved, the AI generates a compelling subject line and preheader text based on the selected stories. It also produces multiple alternative subject lines for consideration.
The team can choose the best subject line or provide feedback to refine it further. This iterative process balances AI automation with editorial judgment.

Writing Newsletter Content Segments
With stories and subject line finalized, the AI writes detailed segments for each top story. It fetches the original markdown and any extracted external sources to create rich, informative content.
The writing style follows a consistent format:
- Recap: A summary of the key points
- Unpacked list: Further details broken down
- Bottom line: A concise takeaway
The AI is guided by prompts that specify tone, voice, formatting, and hyperlinking requirements to ensure the newsletter remains clear and engaging.
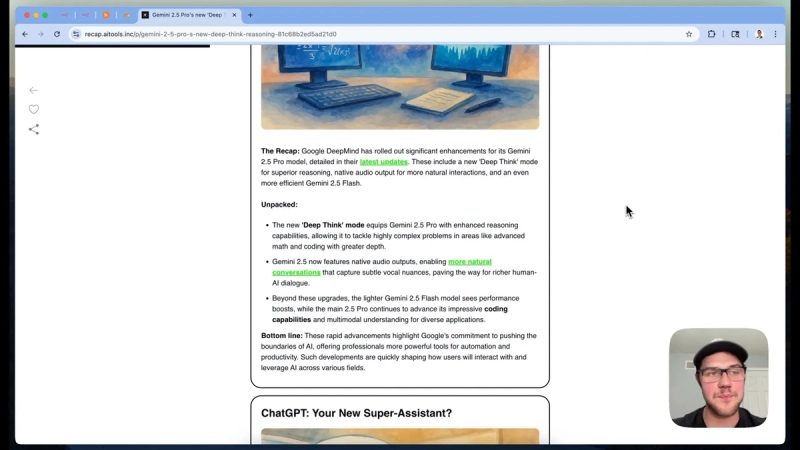
Completing the Newsletter: Intro and Short List
The AI then writes the introduction section, highlighting the top story and providing an overview of the newsletter's contents. It also generates a "short list" of other relevant stories that didn't make the main segments but are still worth sharing.
The short list is carefully curated to avoid duplication with the main stories and includes interesting tidbits for readers who want a broader view of the day's AI news.
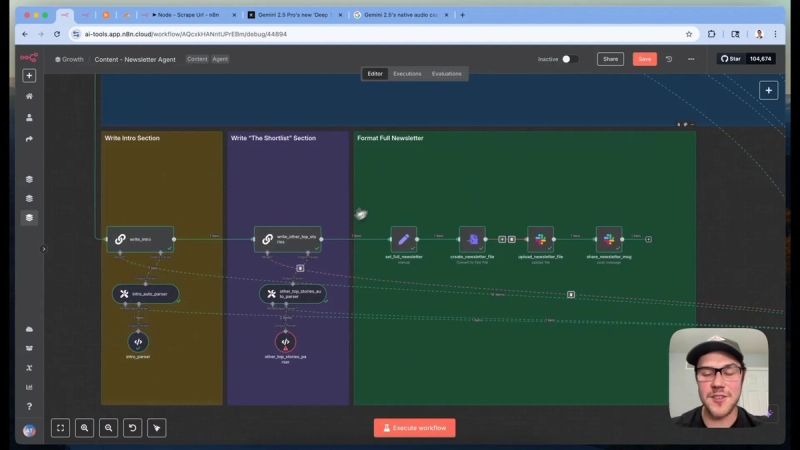
Formatting and Publishing
The final newsletter is formatted in markdown with proper headers, bold text, and contextual links, making it easy to paste into newsletter platforms like Beehive. The system even uploads the formatted newsletter to Slack for easy access by the team.
This streamlined output step completes the automation cycle, delivering a polished newsletter ready for distribution to tens of thousands of subscribers.
Download This Automation
Building a fully automated AI newsletter is achievable by combining intelligent data scraping, AI-driven content selection, and structured writing prompts. This system reduces the need for a content team while maintaining quality through human-in-the-loop feedback.
If you want to build your own AI-powered newsletter or explore other AI automation workflows, join our AI Automation Mastery community. You'll get access to the full n8n template for this automation and a supportive environment to learn and grow your AI skills.





