Working with Twitter's API for serious data projects can quickly become expensive. Fetching details for just 15,000 tweets can cost around $200 per month, and exceeding that limit may lead to a steep increase to $5,000 monthly. For many automation projects, such pricing is not practical. Fortunately, there is a more affordable and flexible alternative. This guide will walk you through building a Twitter scraping system using n8n and Apify that costs roughly 40 cents per thousand tweets scraped.
If you're interested in automating your workflows with this system, consider joining our free AI Automation Community, where you can download the complete n8n automation template and gain access to helpful resources and support from like-minded builders.
Understanding the Twitter Scraping Use Cases
There are three primary ways to scrape Twitter data using this system, each tailored to different needs:
- Scraping Tweets by Username: Collect recent tweets from specific Twitter accounts.
- Scraping Tweets by Search Query: Gather tweets based on keywords or phrases, similar to Twitter's search function.
- Scraping Tweets by Twitter List URL: Extract tweets from a curated list of Twitter accounts, useful for following specific communities or topics.
Each use case is supported by an n8n workflow that interacts with Apify's powerful scraping API to fetch and process the data efficiently.
1. Scraping Tweets by Username
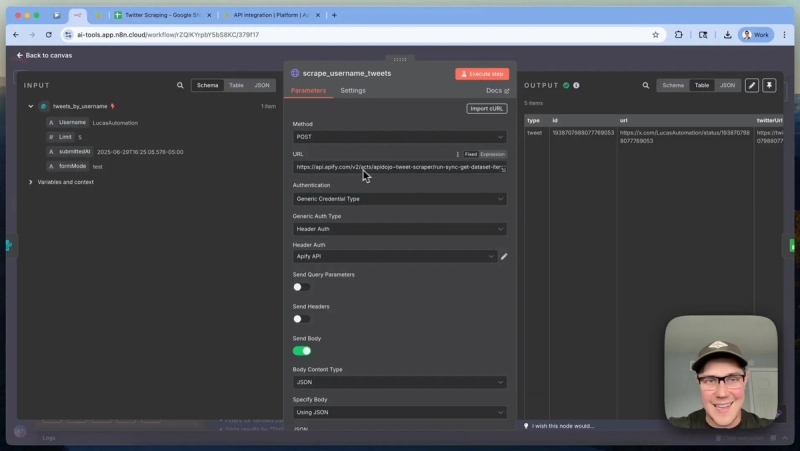
This method is ideal when you want to monitor one or multiple Twitter accounts and collect their latest tweets. The system takes a Twitter username (or multiple usernames in an array) and a limit for the number of tweets to retrieve.
Behind the scenes, it sends a JSON request to Apify's Tweet Scraper v2 actor, specifically maintained by API Dojo. This actor can return up to 1,000 tweets for a low cost compared to Twitter’s official API pricing.
The JSON request includes:
- maxItems: The number of tweets to fetch.
- twitterHandles: An array of Twitter usernames.
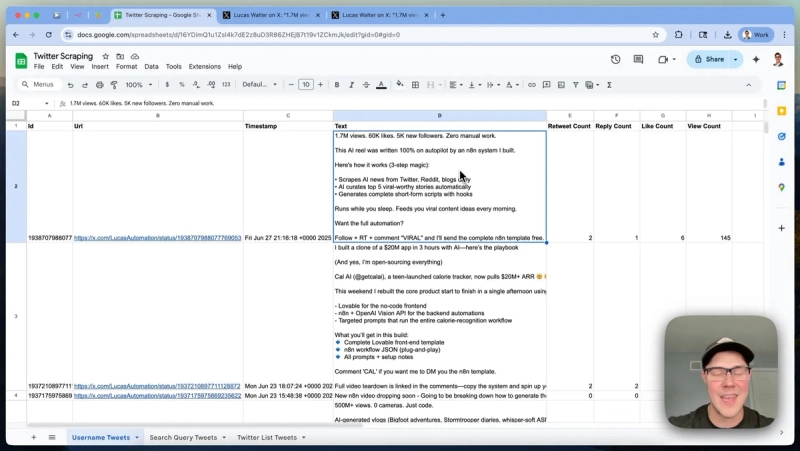
The response contains tweet text, engagement statistics such as retweet count, reply count, and like count, and metadata for each tweet. This data can then be easily appended to a Google Sheet or directed to other storage solutions like Supabase, Airtable, or a custom data lake.
2. Scraping Tweets by Search Query
If you want to collect tweets around specific topics or keywords, scraping by search query is the way to go. This approach mimics the search functionality found on Twitter or X.com.
When building the request for Apify, you provide:
- maxItems: Number of tweets to retrieve.
- searchTerms: An array with search queries (e.g., "released AI research paper").
- filters: Options like only verified users and only Twitter Blue users to reduce spam and low-quality results.
- sortBy: Determines the order of tweets, like top, latest, or by people.
Using these filters is crucial to avoid wasting scraping credits on irrelevant or low-signal tweets. The search query supports Twitter's advanced search syntax, allowing for highly customized scraping.
Once the data is fetched, it is saved into Google Sheets or other databases for further analysis or integration.
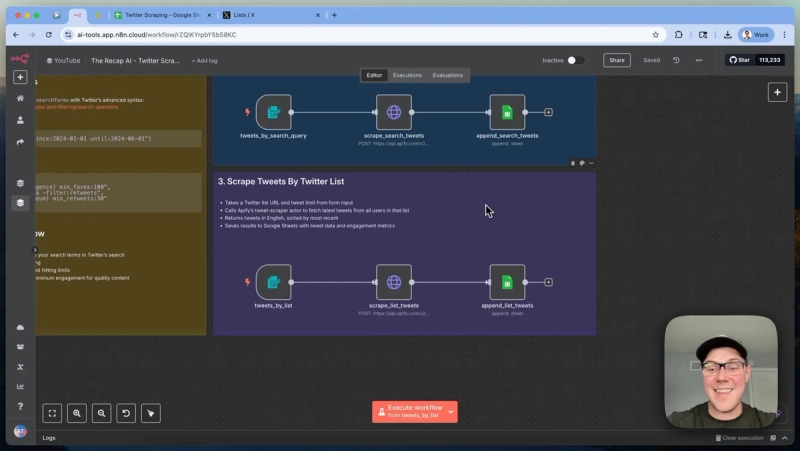
3. Scraping Tweets by Twitter List URL
Scraping by Twitter list URL is especially useful if you have a manually curated list of Twitter accounts related to a niche or industry. Instead of fetching tweets one username at a time, this method pulls tweets from all members of the list in a single stream.
To set this up, you simply provide the URL of the Twitter list and specify the number of tweets to scrape. The system passes this URL to Apify’s actor using the startUrls parameter in the JSON request.
This approach is perfect for building news feeds or monitoring content from a focused group of accounts. For example, it can be used to power newsletters or content aggregation platforms.
Getting Started with Apify and n8n
Apify is a web scraping and automation platform centered around the concept of actors. Actors are specialized tools designed to extract data from specific websites. Think of them as pre-built scrapers or mini-APIs accessible via a single platform.
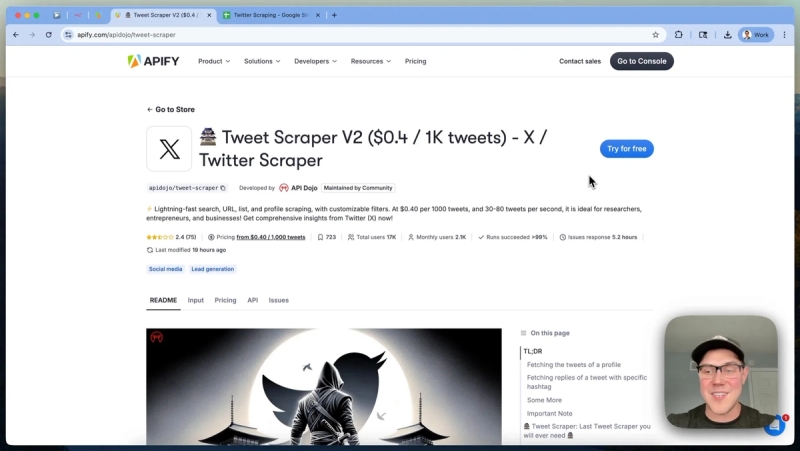
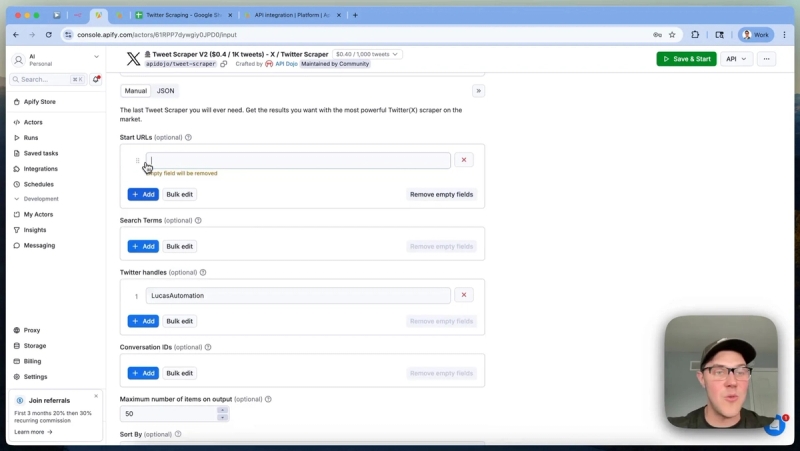
To find Twitter scraping actors, simply search for "Twitter" on Apify’s platform. You will find various community-maintained scrapers for profiles, tweets, and lists. For this system, the Tweet Scraper v2 by API Dojo is used because it offers a balance of functionality and cost.
One of the key advantages of Apify is its pricing model, which is significantly cheaper than Twitter’s official API. For example, Apify charges about $0.40 for every 1,000 tweets scraped, compared to thousands of dollars on Twitter’s API.
How to Set Up Authentication and Make API Requests
To integrate Apify with your n8n workflows, you need to authenticate API requests. Apify supports header-based token authentication. Here’s the process:
- Generate your API token in Apify under Settings > API & Integrations.
- In n8n, create a generic credential with header authentication.
- Set the header name to Authorization and provide your API token as the value.
- Use this credential in your HTTP request nodes when calling Apify’s API.
This setup allows you to securely make POST requests to Apify’s API endpoint that runs actors synchronously and returns scraped data in one JSON response.
Building Dynamic Requests with JSON
When calling Apify’s Tweet Scraper actor, you need to provide a JSON body that specifies what data you want. The JSON structure changes depending on the scraping method:
- By Username: Pass an array of Twitter handles and the max number of tweets.
- By Search Query: Provide search terms, filters like verified users, and sorting options.
- By List URL: Use the startUrls field with Twitter list URLs.
Apify’s web interface features a manual builder that lets you configure these options visually. Once you set your parameters, you can switch to JSON mode and copy the generated request body. This makes it easy to test and iterate without guesswork.
Processing and Storing Scraped Data
After receiving tweet data from Apify, the next step is to store and process it. The example workflows use Google Sheets to append rows with tweet content and engagement metrics. However, you have flexibility to connect this data to tools like:
- Databases such as Supabase or Airtable
- Custom data lakes for large-scale analytics
- Further automation workflows for notifications or content creation
This setup provides a solid foundation for building Twitter-based automation systems customized to your needs.
Building a Production-Ready System: Real-World Use Case
To illustrate the power of this scraping system, consider its use in powering a daily AI newsletter. The system runs on a scheduled trigger every hour, scraping tweets from various sources, including Twitter timelines and curated lists.
The workflow includes a data cleanup step that evaluates each tweet's relevance. Irrelevant tweets are filtered out, and the rest are saved to a data lake. This accumulated data serves as a rich content pool used later to generate newsletter stories.
The newsletter generation workflow:
- Retrieves scraped tweets from the data lake.
- Filters and combines relevant content into plain text.
- Passes the text to a large language model (LLM) for summarization and story creation.
- Builds a compelling subject line and sections for the newsletter.
- Delivers the final newsletter to thousands of subscribers.
This example shows how scraping Twitter data at scale can directly feed into valuable business processes like content marketing.
Why Choose This Twitter Scraping System?
Compared to Twitter’s official API, this method:
- Costs significantly less, around 40 cents per 1,000 tweets.
- Offers flexibility in scraping tweets by username, search query, or curated lists.
- Leverages Apify’s scalable actor platform with community-supported scrapers.
- Integrates smoothly with n8n for building automated workflows without heavy coding.
- Allows easy customization and expansion to suit varied automation needs.
Download This n8n Workflow
If you want to jumpstart your automation projects with this Twitter scraping system, join our free AI Automation Mastery community. You’ll get access to this complete n8n automation template, detailed setup instructions, and a network of builders sharing their automation workflows.





