Web scraping is an essential tool for gathering content from the internet, especially when you need to feed data into large language models (LLMs) or automate content creation like SEO-friendly blog posts and newsletters. In this guide, I will walk you through how to build a robust web scraping pipeline using three key components: n8n, Firecrawl API, and rss.app.
This pipeline will scrape virtually any piece of web content and instantly transform it into clean, markdown-formatted, LLM ready output. By the end, you will also see an example of a production-ready workflow used for automating content ingestion at scale.
Before diving into the details, consider joining our AI Automation Community. There, you can get the complete n8n automation template for this scraping system and access resources to build your own AI-powered workflows.
Step 1: Setting Up the Initial Web Scraping Automation in n8n
The first step is to create a simple automation in n8n that acts as a web scraping pipeline for news-related content. While the example here uses a Google News feed, the same setup can scrape any web content.
Start by configuring an HTTP Request node that calls the rss.app API to aggregate news stories from your chosen feed. For instance, a Google News custom RSS feed URL can be used here to pull the latest news articles.
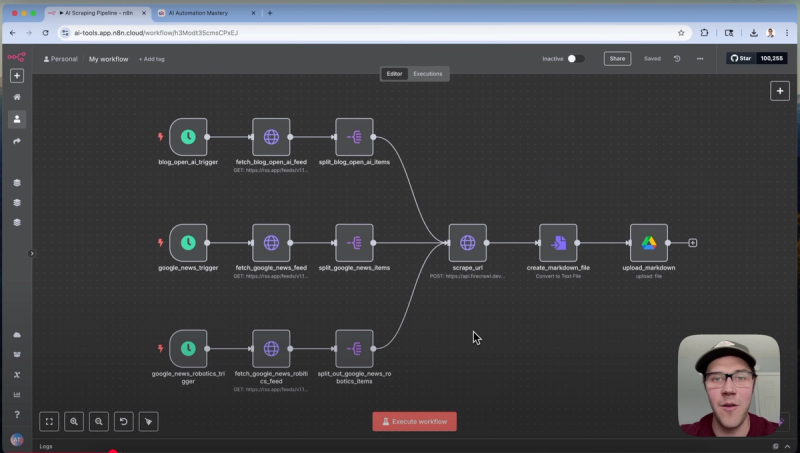
This node fetches a list of news story URLs, which are then cleaned up and passed into a second HTTP Request node. This secondary node is responsible for doing the heavy lifting by scraping the actual web pages using the Firecrawl API.
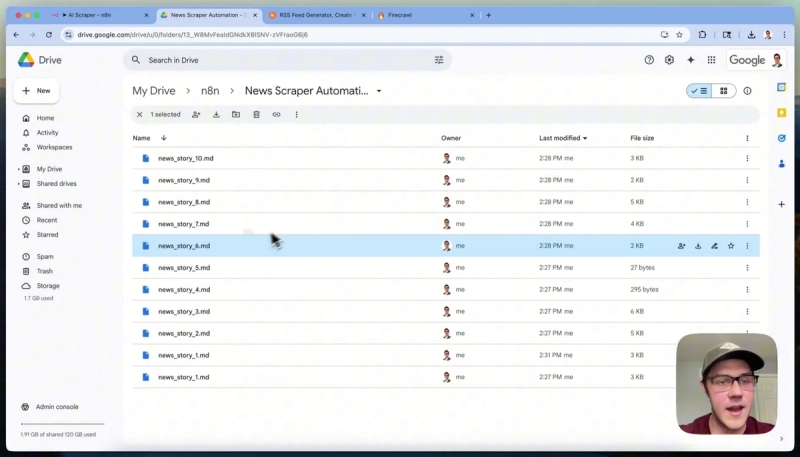
After scraping, the output is in markdown format, which is ideal for LLM consumption. Each scraped article is converted into a markdown text file, then uploaded to a specified Google Drive folder for easy access and further processing.
Step 2: Scraping Additional Sources
This workflow is flexible enough to handle different content sources. For example, instead of scraping Google News, you can configure the workflow to scrape articles from the OpenAI blog by changing the RSS feed URL in the HTTP Request node to point to the OpenAI blog’s RSS feed.
Once the feed is fetched, the workflow splits the list of articles into individual items, then passes each URL to the Firecrawl API for scraping. The output once again is clean markdown, saved and organized in Google Drive for easy retrieval.
This approach can be repeated for any other RSS feed or URL list, making it a universal scraping pipeline.
Step 3: Building a Custom RSS Feed for Robotics News
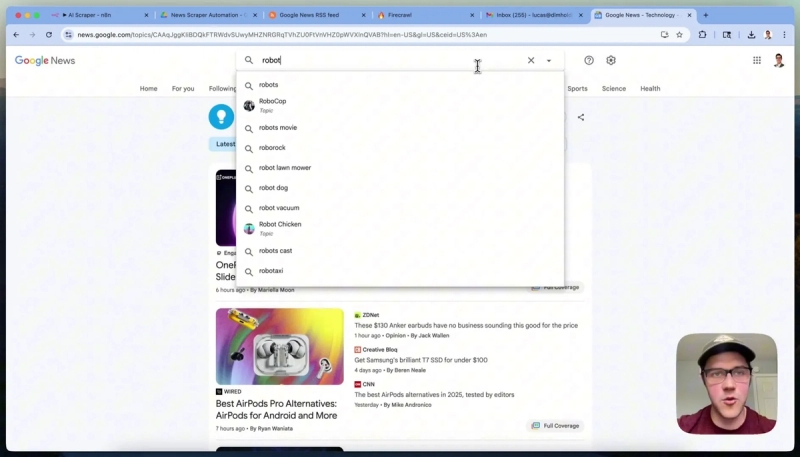
To extend the workflow, let's build a custom feed for robotics news. First, go to Google News and filter articles under the Technology category by searching for “robotics.” Copy the URL from the browser.
Next, navigate to rss.app and create a new feed by pasting the copied Google News URL. Generate the feed and verify that the returned articles are relevant to robotics.
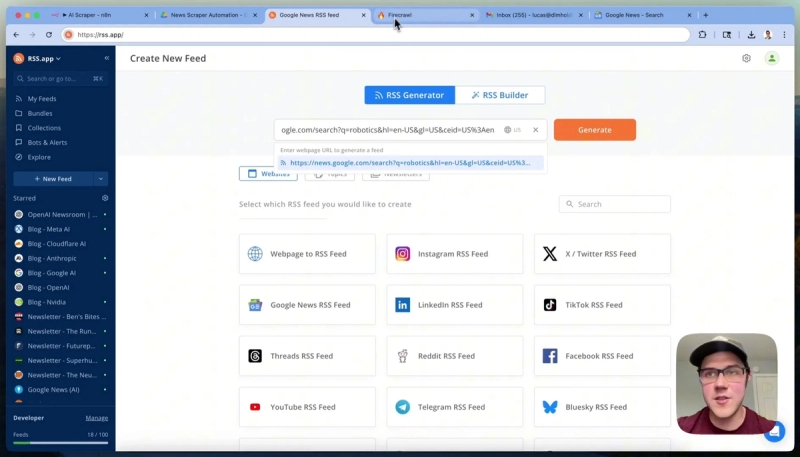
Save this feed and ensure you select the JSON format for the feed URL, which is optimal for processing in n8n. Opening this JSON feed in a browser will display the structured data that n8n will consume.
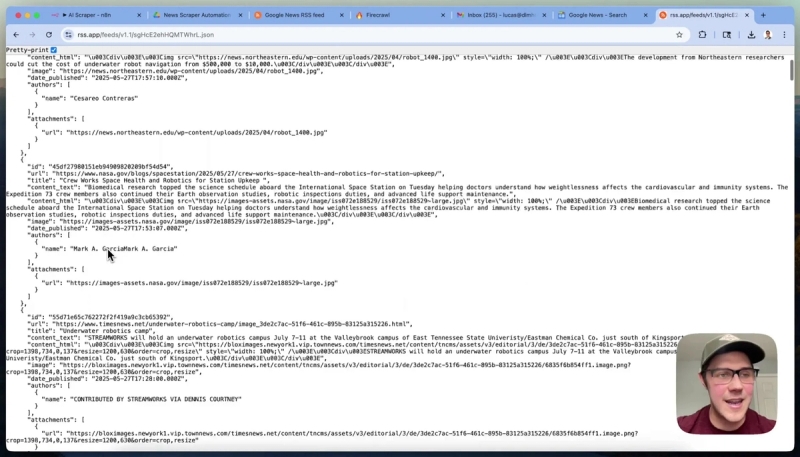
Step 4: Automate Fetching and Spliting RSS Data in n8n
Back in n8n, add a new schedule trigger node to run the workflow every couple of hours. Then add an HTTP Request node configured with the RSS feed URL from rss.app set to GET method. Executing this node should fetch the latest robotics news feed data.
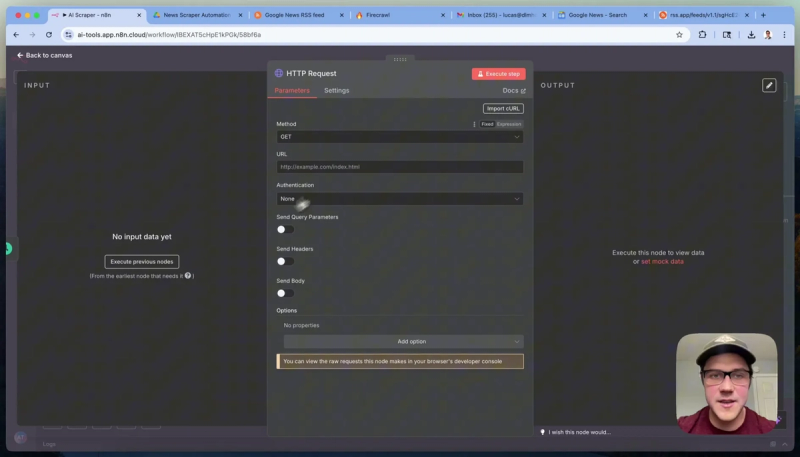
The next step is to clean up the data by splitting the single list of articles into individual items for processing. Use the Split Out node in n8n to transform the array of articles into separate items, enabling the Firecrawl API to scrape each URL individually.
You can adjust the number of items processed during testing by limiting the feed output in rss.app or the split node settings.
Step 5: Integrating the Firecrawl API for Web Content Scraping
The Firecrawl API is the core scraping engine. It receives URLs and returns clean, markdown-formatted content ready for LLM use. To set this up:
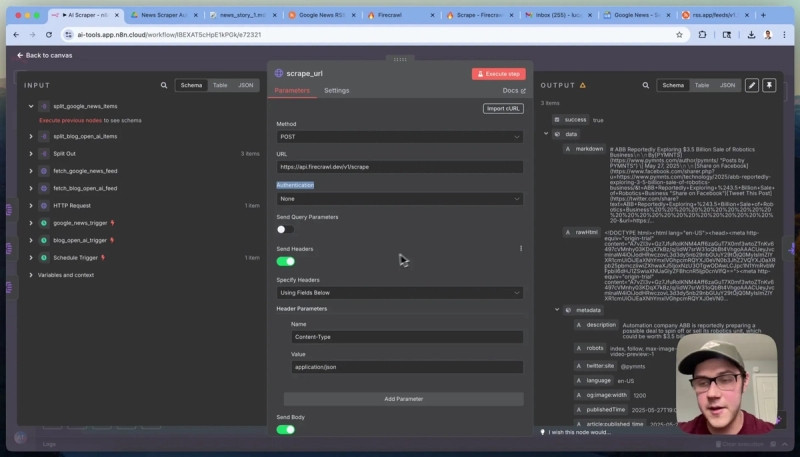
- Change the HTTP method to POST.
- Set the URL to Firecrawl’s scrape endpoint: https://api.firecraw.dev/v1/scrape.
- Set the body content type to JSON and specify the URL dynamically by referencing each split item’s URL.
- Specify headers with Content-Type: application/json.
- Pass additional parameters to optimize scraping, such as requesting markdown, raw HTML, and links, and excluding unwanted tags like navigation bars and footers.
- Set onlyMainContent to true to focus the scrape on the article body.
- Optionally, use the jsonOptions field to provide a prompt that instructs Firecrawl to extract only the main article content verbatim, removing promotional text and buttons.
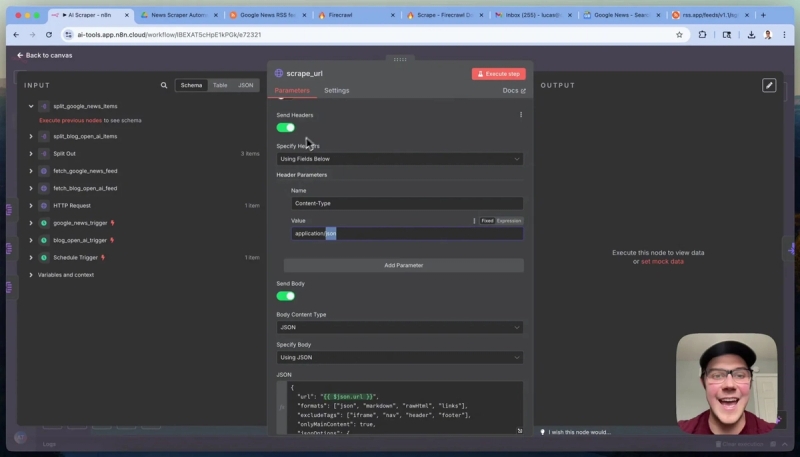
This setup ensures you get clean, relevant content optimized for your downstream AI applications.
Step 6: Configuring Firecrawl API Authentication
Firecrawl requires a bearer token for API authentication. To avoid 401 errors:
- Copy the header name “authorization” exactly as specified in Firecrawl’s docs.
- In n8n, create a new generic credential with Header auth type.
- Paste the header name as “Authorization”.
- Set the value as bearer YOUR_FIRECRAWL_API_KEY, where YOUR_FIRECRAWL_API_KEY is your actual API key from your Firecrawl account.
- Save the credential and assign it to the HTTP node responsible for calling Firecrawl.
Storing credentials this way simplifies reuse across multiple workflows and keeps your API keys secure.
Step 7: Converting Scraped Markdown Content to Files and Uploading to Google Drive
Once Firecrawl returns the markdown content, the next step is to convert this JSON text into actual markdown files. Use n8n’s Convert to File node with the “Convert to Text File” operation.
Specify the path to the markdown content in the JSON response, usually data.down or data.json depending on whether you use the JSON Options prompt.
Rename each file systematically, for example, “news_story_1.md”, “news_story_2.md” and so on, using expressions based on the item index for clarity.
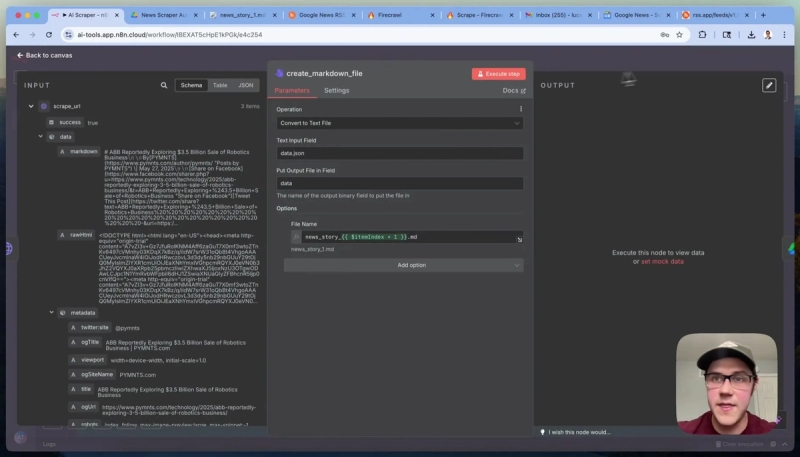
Finally, upload these markdown files to Google Drive using the Google Drive node. Select the resource as “File”, operation as “Upload”, and map the file data from the previous node output.
This completes the scraping-to-storage pipeline, making your scraped content easy to access and ready for further AI-driven content creation or prompting.
Step 8: Example of a Production-Scale AI-Enabled Scraping Workflow
To put this all together, here is a glimpse into a production AI-enabled scraping workflow used in a real business setting for an AI newsletter:
- Multiple paths scrape news articles from various sources such as Nvidia blog, Google blog, Anthropics blog, Reddit, Hacker News, and Google News.
- Each scraped story is assigned a unique identifier for tracking through the content pipeline.
- Before scraping, the system checks an S3 bucket to avoid redundant scraping and save API credits.
- Content is filtered using AI prompts to ensure relevance to the target audience, excluding unrelated or low-quality articles.
- Additional enrichment extracts external source links from articles for future scraping or citation.
- Scraped and enriched content is stored in centralized cloud storage (S3), facilitating easy access for content teams and automation.
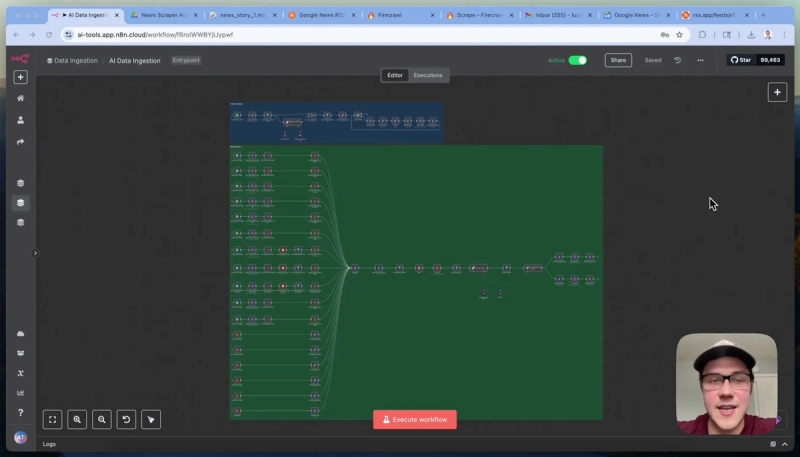
This example shows how scalable and adaptable these tools are when combined, enabling automated, intelligent content pipelines.
Conclusion
We've shown you how to combine n8n, Firecrawl, and rss.app to build a flexible, powerful web scraping pipeline that outputs clean, LLM-ready markdown files.
Whether you are scraping news articles, blog posts, or any web content, this approach simplifies content ingestion and automates tedious tasks, freeing you to focus on content creation and analysis.
If you are interested in learning how to build more automations like this, consider joining our free community AI Automation Mastery — Our vision is to bring together forward-thinking professionals, entrepreneurs, and automation enthusiasts who are ready to harness the power of AI to transform their workflows and businesses.





