Running advanced AI models like GPT-4 typically requires cloud access, API keys, and ongoing costs. But what if you could run a powerful AI agent entirely on your own computer, without any cloud dependencies or fees? Using the newly released open-source GPT-OSS model, combined with Ollama and n8n, you can do just that. This guide walks you through setting up your own local AI agent that performs on par with GPT-4 level models, all for free and fully self-hosted.
Want to get hands-on with building your own AI automations and agents? Join our Free AI Automation Community to access free workflows, templates, and expert support from fellow AI builders. It’s the perfect place to start creating AI-powered solutions for your business or projects.
Overview: Running GPT-OSS Locally with n8n and Ollama
This setup involves four main steps:
- Installing and running n8n locally using Docker
- Installing Ollama, a tool to manage and run large language models (LLMs) on your device
- Downloading and running the GPT-OSS model inside Ollama
- Connecting Ollama’s chat model to n8n to build AI workflows and agents
Each part is designed to keep everything running on your machine, eliminating the need for API keys or paid cloud services. Let’s dive into each step so you can start building your own AI-powered automations.
Step 1: Set Up n8n Locally with Docker
n8n is a popular automation platform that lets you create workflows and AI agents visually. To host it locally, Docker is the easiest way to manage the installation and keep everything isolated.
First, make sure you have Docker Desktop installed on your computer. Docker runs on Windows, macOS (including Apple Silicon), and Linux. If you don’t have it yet, download Docker from the official site and follow the installation wizard for your operating system.
Once Docker is installed and running, open your terminal. The next crucial step is to create a Docker volume to store your n8n data persistently. This volume keeps your workflows, execution logs, and debug data safe even if you restart the container or reboot your system.
Use the command docker volume create n8n_data to create this volume. You can verify it by running docker volume ls which will list all volumes on your machine.
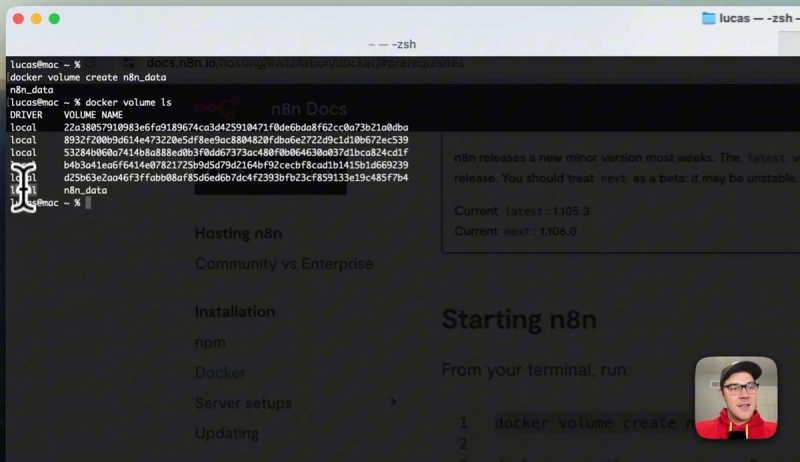
Next, start the n8n Docker container by running the provided Docker command that binds the volume you created and exposes n8n on your local machine. Once it starts, you’ll see a message indicating the editor is accessible via a localhost URL.
Open your browser and navigate to the given localhost address. If this is your first time, create a local account and skip the onboarding to access your n8n dashboard. You now have a fully functional instance of n8n running locally and ready to integrate with AI models.
Step 2: Install Ollama to Manage Local AI Models
Ollama is a lightweight software that simplifies downloading, managing, and interacting with large language models on your own device. Instead of writing complex scripts or managing dependencies manually, Ollama provides a smooth interface for running models like GPT-OSS.
Go to the official Ollama website and download the version compatible with your operating system. For macOS users, this will be a DMG file you can drag into your Applications folder.
Once installed, Ollama is ready to help you pull in and run AI models locally.
Step 3: Download and Run GPT-OSS Model in Ollama
GPT-OSS is OpenAI’s first open-source language model released since GPT-2, offering GPT-4-level performance without any cost or cloud dependency. To get it running, search for “GPT-OSS” in Ollama’s model library or use the exact model name from the official listings.
In your terminal, run ollama run gpt-oss:latest to download and start the model. This command fetches the model weights to your machine and prepares it to respond to prompts locally.
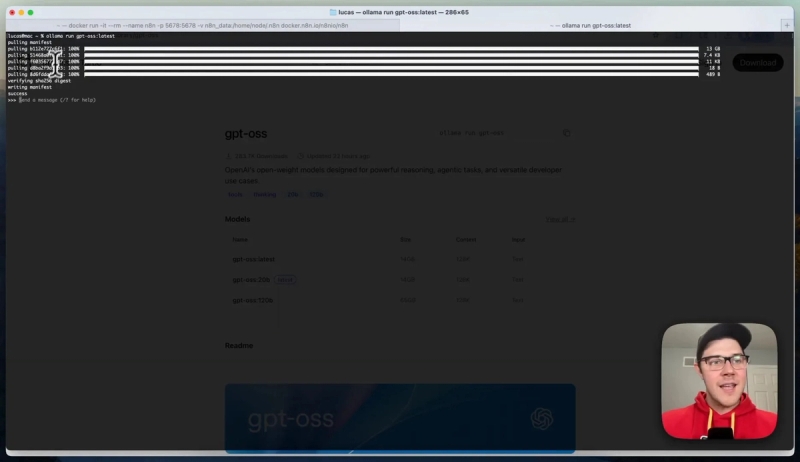
Once the download completes, you can test it by asking it to generate text, such as a poem or a short story. The responses come quickly even on modest hardware like an Apple M2 MacBook, demonstrating the model’s efficiency.
Step 4: Connect Ollama’s Chat Model to n8n for AI Workflows
To integrate GPT-OSS with n8n, you need to run the Ollama server locally. This server hosts the chat model accessible via an API that n8n can connect to.
Open a new terminal window and run ollama serve. When you see a message indicating it’s listening on 127.0.0.1, the server is ready.
Next, head back to your n8n instance and create a new workflow. Add a manual trigger and then an LLM chain node to make a chat call to Ollama.
When setting up the Ollama chat model credential in n8n, don’t use the default localhost URL. Because n8n runs inside Docker, you must use http://host.docker.internal:11434 (the port Ollama server listens on) as the base URL to allow Docker containers to communicate with services on your host machine.
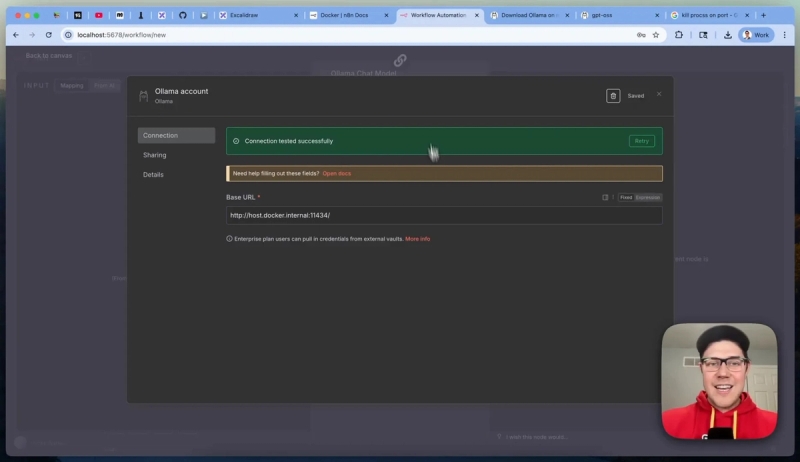
After saving this credential, n8n can successfully connect to the Ollama server and send chat prompts to GPT-OSS. You can now build automations that generate content, analyze data, or perform any AI-driven task fully locally.
Building AI Agents Powered by GPT-OSS in n8n
With n8n connected to Ollama’s GPT-OSS model, you can create AI agents that handle complex workflows. For example, you can set up a chat trigger node linked to an AI agent node, add memory for context retention, and enable tool integrations to extend functionality.
One practical use case is generating LinkedIn posts that compare services like n8n versus make.com. The agent can think through the pros and cons, call tools for research or formatting, and output polished markdown content ready for publishing.
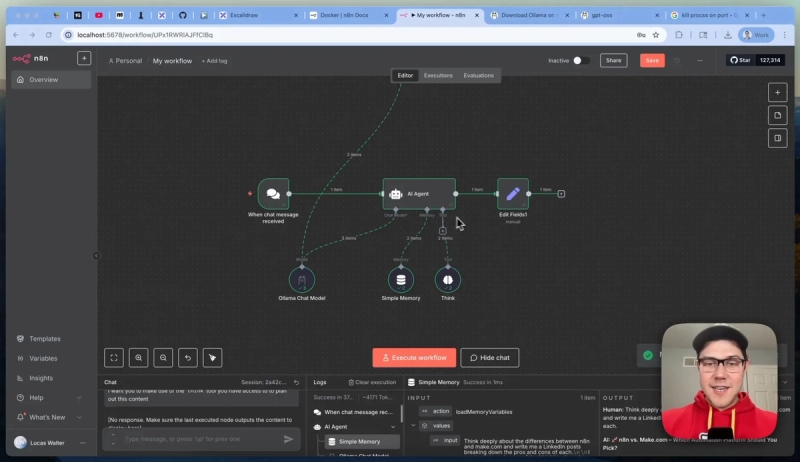
This approach enables powerful automation without relying on external APIs, making it ideal for industries with strict privacy requirements such as healthcare, legal, or defense.
Why Run AI Models Locally?
- Cost Savings: No API fees or cloud costs since everything runs on your own hardware.
- Data Privacy: Sensitive information never leaves your machine, crucial for regulated industries.
- Flexibility: Full control over model versions, configurations, and integrations.
- Offline Access: AI capabilities are available even without internet connectivity.
While local models can be slower than cloud-based APIs depending on your hardware, the trade-off is worth it for many applications where privacy and cost are priorities. If you have a GPU, inference speeds will improve significantly.
Get Started with Your Own Local AI Agent
This setup demonstrates that powerful AI doesn’t have to be locked behind expensive APIs or cloud services. With n8n, Ollama, and GPT-OSS, you can build intelligent agents that run entirely on your machine for zero cost.
Ready to explore the possibilities? Join our AI Automation Mastery community to get free access to this n8n workflow template and many other AI automation resources. Collaborate with other builders, share your projects, and accelerate your AI journey.





