
What is Reka?
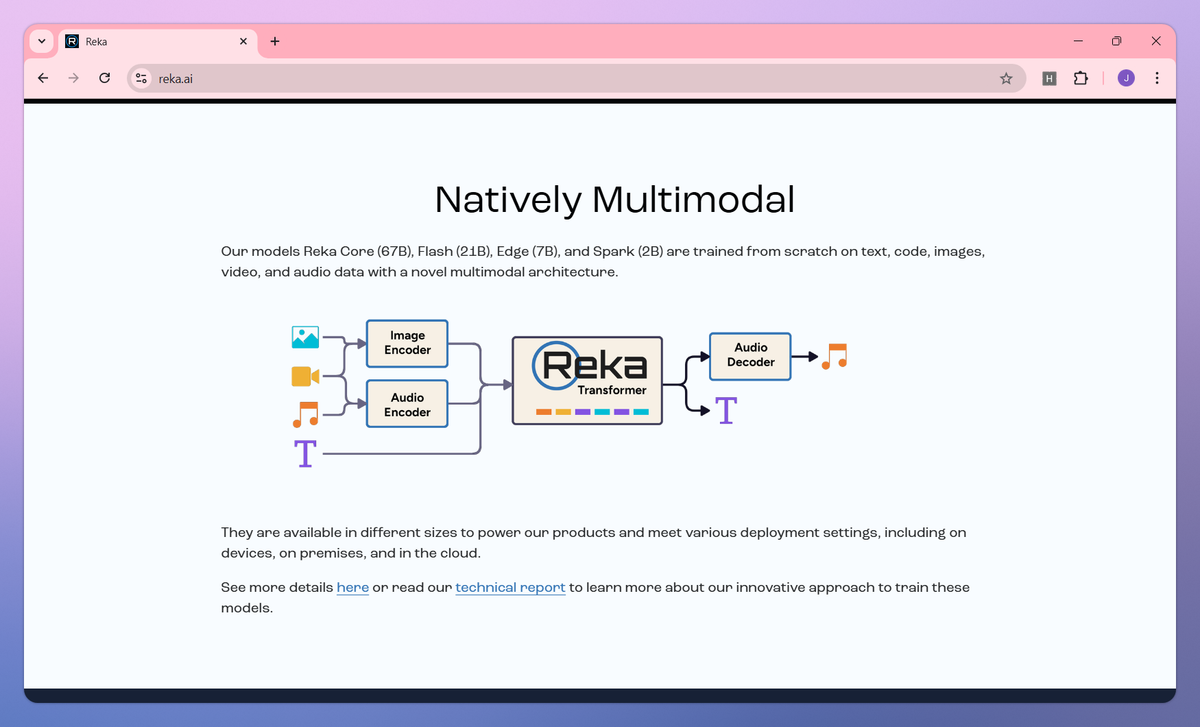
Reka is a multimodal AI tool that understands text, code, images, video, and audio inputs. It processes multiple data formats, responds to detailed visual content, and deploys flexibly across devices, on-premises servers, or cloud environments to help developers and data scientists build responsive applications with minimal setup time.
What sets Reka apart?
Reka distinguishes itself with its novel multimodal architecture trained from scratch on diverse data formats, making it ideal for businesses building high-performing AI agents that can see, hear, and interact naturally. The range of model sizes—from compact Spark (2B) to robust Core (67B)—helps programmers match computing resources with project demands, whether implementing on small mobile devices or tackling complex data understanding tasks. Reka's transparent pricing structure across all deployment options gives startups and enterprise teams the flexibility to scale as their AI needs grow.
Reka Use Cases
- Multimodal content analysis
- Document information retrieval
- AI model deployment
- Image and video understanding
Who uses Reka?
Features and Benefits
'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_1182_27871'%20x1='12.385'%20y1='12.5872'%20x2='48.2299'%20y2='32.1489'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20offset='0.0938117'%20stop-color='%2352EB07'/%3e%3cstop%20offset='0.347535'%20stop-color='%233EF040'/%3e%3cstop%20offset='0.768595'%20stop-color='%2300FFF7'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e) Processes and understands text, images, video, and audio content through natively multimodal AI models trained on diverse data types. Multimodal Understanding
Processes and understands text, images, video, and audio content through natively multimodal AI models trained on diverse data types. Multimodal Understanding - Deploy models anywhere including on cloud services, on-premises infrastructure, or directly on devices based on specific requirements. Flexible Deployment
- Access Reka's capabilities through Python SDK or HTTP API with straightforward integration options for applications. Developer API
- Choose from multiple model sizes including Core, Flash, Edge, and Spark to balance performance needs against computational requirements. Scalable Model Options
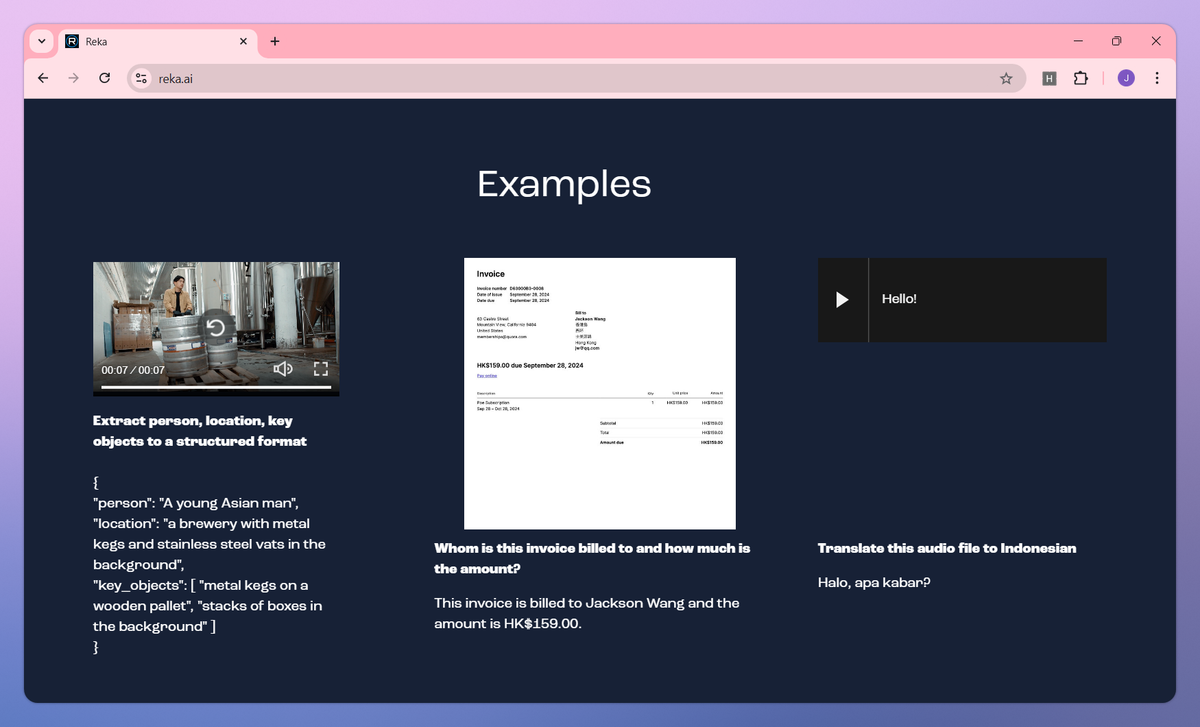
- Extract structured information from images and videos, identifying people, objects, text, and relationships between elements. Visual Content Analysis
Reka Pros and Cons
'/%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M16.0466%206.18948C16.3178%206.46068%2016.3178%206.90038%2016.0466%207.17157L8.40771%2014.8105C8.13652%2015.0817%207.69682%2015.0817%207.42562%2014.8105L3.9534%2011.3382C3.6822%2011.067%203.6822%2010.6273%203.9534%2010.3561C4.2246%2010.085%204.66429%2010.085%204.93549%2010.3561L7.91667%2013.3373L15.0645%206.18948C15.3357%205.91828%2015.7754%205.91828%2016.0466%206.18948Z'%20fill='%23343634'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_1569_59'%20x1='0.289288'%20y1='-0.211567'%20x2='31.2845'%20y2='15.6364'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20offset='0.0938117'%20stop-color='%2352EB07'/%3e%3cstop%20offset='0.347535'%20stop-color='%233EF040'/%3e%3cstop%20offset='0.768595'%20stop-color='%2300FFF7'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e) Fast and accurate voice cloning produces natural-sounding translations
Fast and accurate voice cloning produces natural-sounding translations - Simple and intuitive interface requires minimal technical expertise
- Ability to edit translations and transcripts provides precise control
- Quickly translates content into multiple languages simultaneously
- Real-time preview and rapid export speeds streamline workflow
 Premium features like lip sync only available in more expensive plans
Premium features like lip sync only available in more expensive plans - Translated voices sometimes lack emotional range and sound monotonous
- Minute counting rounds up partial minutes to full minutes
- Customer support can be slow to respond to issues
- Translation quality inconsistent for less common languages
Pricing
- Compact model ideal for on-device execution
- $0.05 per 1M input tokens
- $0.05 per 1M output tokens
- $0.00025 per image
- $0.00025 per second of video
- $0.0025 per minute of audio
- Lightweight model for local or latency sensitive applications
- $0.1 per 1M input tokens
- $0.1 per 1M output tokens
- $0.0005 per image
- $0.0005 per second of video
- $0.005 per minute of audio
- Fast and cost-efficient model for most tasks
- $0.2 per 1M input tokens
- $0.8 per 1M output tokens
- $0.001 per image
- $0.001 per second of video
- $0.01 per minute of audio
- Superior capabilities for complex tasks
- $2 per 1M input tokens
- $2 per 1M output tokens
- $0.002 per image
- $0.002 per second of video
- $0.02 per minute of audio
Reka Alternatives







