
What is Coqui TTS?
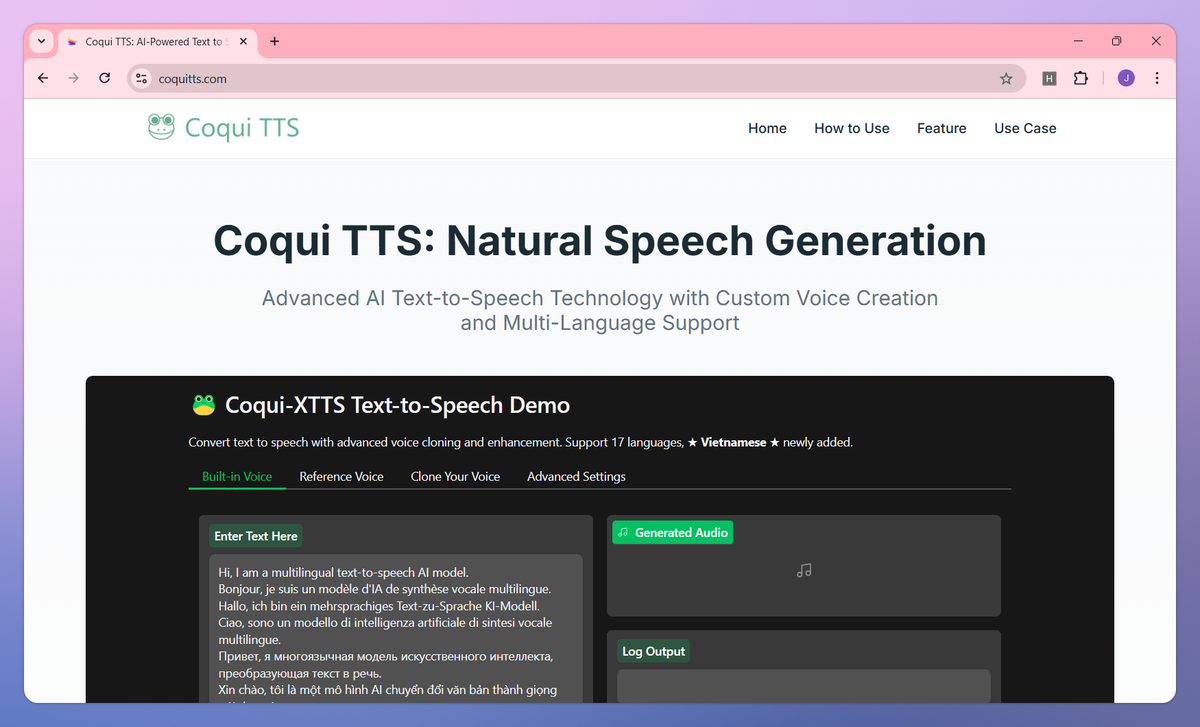
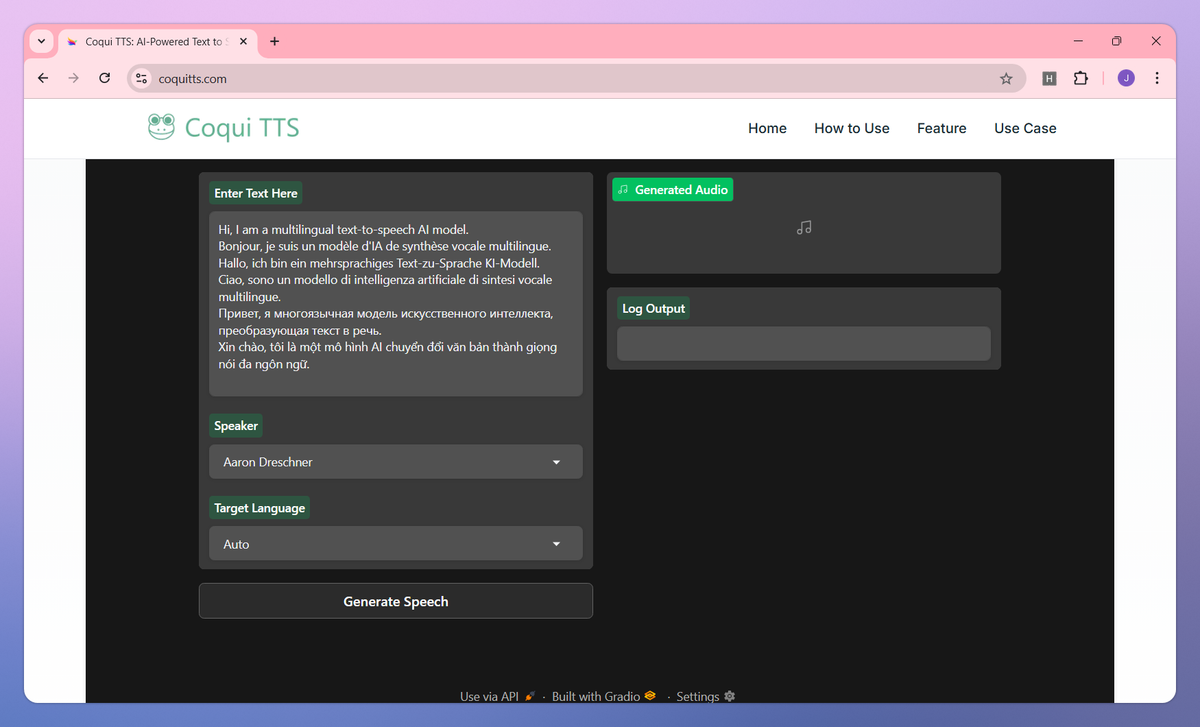
Coqui TTS is an AI-powered text-to-speech platform that converts written text into natural-sounding speech across 17 languages including English, Spanish, French, and Vietnamese. It clones voices from 3-second audio samples, creates custom vocal personas, and adjusts speech parameters for developers building AI assistants, educators producing narrated content, game designers crafting character voices, and accessibility specialists supporting visually impaired users.
What sets Coqui TTS apart?
Coqui TTS sets itself apart with real-time voice synthesis that allows content creators to generate speech instantly while making adjustments. This precise control over voice characteristics at the word and sentence level proves beneficial for voice acting studios needing to achieve specific tonal qualities in their productions. The platform's voice version management system gives podcast producers a clear advantage when comparing different vocal performances for their audio content.
Coqui TTS Use Cases
- Custom voice creation
- Accessibility text narration
- Educational content voiceover
- Rapid voice cloning
- Multi-language translation
Who uses Coqui TTS?
Features and Benefits
'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_1182_27871'%20x1='12.385'%20y1='12.5872'%20x2='48.2299'%20y2='32.1489'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20offset='0.0938117'%20stop-color='%2352EB07'/%3e%3cstop%20offset='0.347535'%20stop-color='%233EF040'/%3e%3cstop%20offset='0.768595'%20stop-color='%2300FFF7'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e) Clone voices from just 3-second audio samples to create personalized voice synthesis for your projects. Rapid Voice Cloning
Clone voices from just 3-second audio samples to create personalized voice synthesis for your projects. Rapid Voice Cloning - Access text-to-speech capabilities in 17 languages including English, Spanish, French, Chinese, and Japanese. Multi-Language Support
- Design unique vocal personas with precise control over characteristics like pace, emotion, pitch, and loudness. Custom Voice Creation
- Generate natural-sounding speech instantly for applications requiring immediate audio feedback. Real-Time Processing
- Deploy the generated voices freely in business applications, social media platforms, and commercial projects. Commercial Usage
Coqui TTS Pros and Cons
'/%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M16.0466%206.18948C16.3178%206.46068%2016.3178%206.90038%2016.0466%207.17157L8.40771%2014.8105C8.13652%2015.0817%207.69682%2015.0817%207.42562%2014.8105L3.9534%2011.3382C3.6822%2011.067%203.6822%2010.6273%203.9534%2010.3561C4.2246%2010.085%204.66429%2010.085%204.93549%2010.3561L7.91667%2013.3373L15.0645%206.18948C15.3357%205.91828%2015.7754%205.91828%2016.0466%206.18948Z'%20fill='%23343634'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_1569_59'%20x1='0.289288'%20y1='-0.211567'%20x2='31.2845'%20y2='15.6364'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20offset='0.0938117'%20stop-color='%2352EB07'/%3e%3cstop%20offset='0.347535'%20stop-color='%233EF040'/%3e%3cstop%20offset='0.768595'%20stop-color='%2300FFF7'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e) Produces high quality voice and audio output
Produces high quality voice and audio output - Generates audio content quickly and efficiently
- Effectively fixes audio breaks and dropped words in recordings
- Works well for patching and repairing existing audio content
 Local system setup process could be more streamlined
Local system setup process could be more streamlined - Multiple generation attempts sometimes needed for optimal results
- Limited functionality for generating full sentences from scratch
- Requires technical knowledge to set up and use effectively
Coqui TTS Alternatives







