
What is AnyParser?
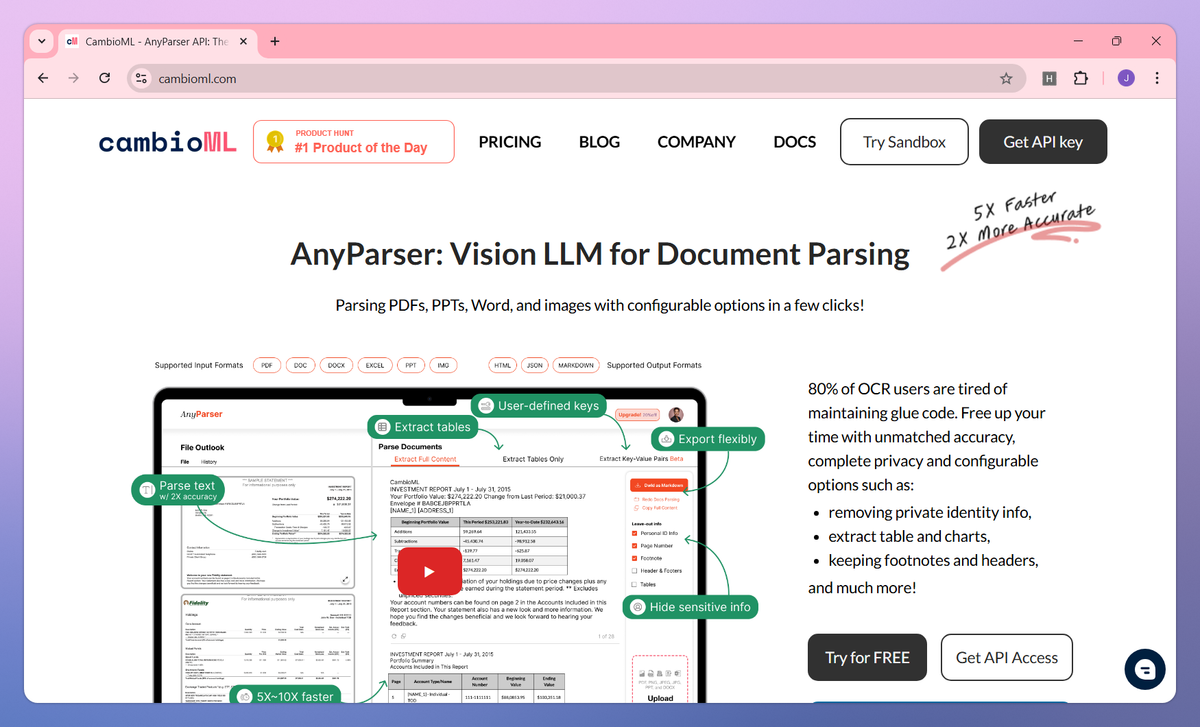
AnyParser is a real-time document extraction tool that converts PDFs, Office files, and images into structured data. It processes full document content, extracts tables while maintaining accuracy, and identifies key-value pairs to help financial analysts and researchers transform unstructured documents into actionable insights.
What sets AnyParser apart?
AnyParser sets itself apart with its privacy-first approach and configurable extraction settings, allowing banking professionals and compliance officers to protect sensitive information while customizing output formats. The tool's Vision Language Model technology recognizes complex document layouts with twice the precision of traditional OCR models, making it ideal for logistics companies dealing with varied shipping documents. Its user-friendly API enables banking institutions to integrate parsed data directly into existing systems, creating seamless document processing workflows.
AnyParser Use Cases
- Document data extraction
- Table recognition conversion
- Privacy-focused parsing
- Business document automation
Who uses AnyParser?
Features and Benefits
'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_1182_27871'%20x1='12.385'%20y1='12.5872'%20x2='48.2299'%20y2='32.1489'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20offset='0.0938117'%20stop-color='%2352EB07'/%3e%3cstop%20offset='0.347535'%20stop-color='%233EF040'/%3e%3cstop%20offset='0.768595'%20stop-color='%2300FFF7'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e) Process various file types including PDFs, Office documents (DOCX, PPTX), and images (PNG, JPG, JPEG) to extract text, tables, and visual data. Multi-format Document Support
Process various file types including PDFs, Office documents (DOCX, PPTX), and images (PNG, JPG, JPEG) to extract text, tables, and visual data. Multi-format Document Support - Extract data with up to 2x greater precision than traditional OCR models through advanced vision language models that maintain document layout and structure. Enhanced Parsing Accuracy
- Safeguard sensitive information with privacy-focused processing and optional PII redaction during document extraction. Privacy Protection
- Control exactly what content gets extracted with configurable options for including or omitting page numbers, headers, footers, figures, and charts. Customizable Extraction
- Connect with existing systems through both synchronous and asynchronous API endpoints that allow for flexible document processing based on complexity and size. API Integration
AnyParser Pros and Cons
'/%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M16.0466%206.18948C16.3178%206.46068%2016.3178%206.90038%2016.0466%207.17157L8.40771%2014.8105C8.13652%2015.0817%207.69682%2015.0817%207.42562%2014.8105L3.9534%2011.3382C3.6822%2011.067%203.6822%2010.6273%203.9534%2010.3561C4.2246%2010.085%204.66429%2010.085%204.93549%2010.3561L7.91667%2013.3373L15.0645%206.18948C15.3357%205.91828%2015.7754%205.91828%2016.0466%206.18948Z'%20fill='%23343634'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_1569_59'%20x1='0.289288'%20y1='-0.211567'%20x2='31.2845'%20y2='15.6364'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20offset='0.0938117'%20stop-color='%2352EB07'/%3e%3cstop%20offset='0.347535'%20stop-color='%233EF040'/%3e%3cstop%20offset='0.768595'%20stop-color='%2300FFF7'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e) Saves significant time by automating document parsing and data extraction
Saves significant time by automating document parsing and data extraction - High accuracy rate when extracting data from various file formats
- Easy to use interface after initial setup
- Flexible parsing system handles multiple data formats effectively
- Excellent customer support with fast response times
 Steep learning curve for initial setup and rule creation
Steep learning curve for initial setup and rule creation - Limited data retention and storage capabilities
- Complex JSON data handling can be confusing
- Parsing accuracy drops with complex HTML formatting
- Potential security concerns for sensitive business data
Pricing
Free Trial- 2,000 pages included
- Additional pages at $0.24 per page
- Auto-capture tables and transform to markdown
- Monthly Pay as you go
- First month money back guarantee
- No hidden fees
- 10,000 pages included
- Additional pages at $0.12 per page
- All Starter features
- Customization services available
- Customized client onboarding
- All Starter and Pro features
- Host on your own private servers
- Dedicated Account Manager
- Custom Integrations and API Responses
- Personalized 1-1 team training
AnyParser Alternatives



