
What is Cerebrium?
Cerebrium is a serverless AI infrastructure platform that helps developers deploy and scale machine learning applications. It processes requests in milliseconds, offers pay-per-use pricing down to the millisecond, and automatically scales resources based on demand to help machine learning engineers and data scientists deploy models without managing complex infrastructure.
What sets Cerebrium apart?
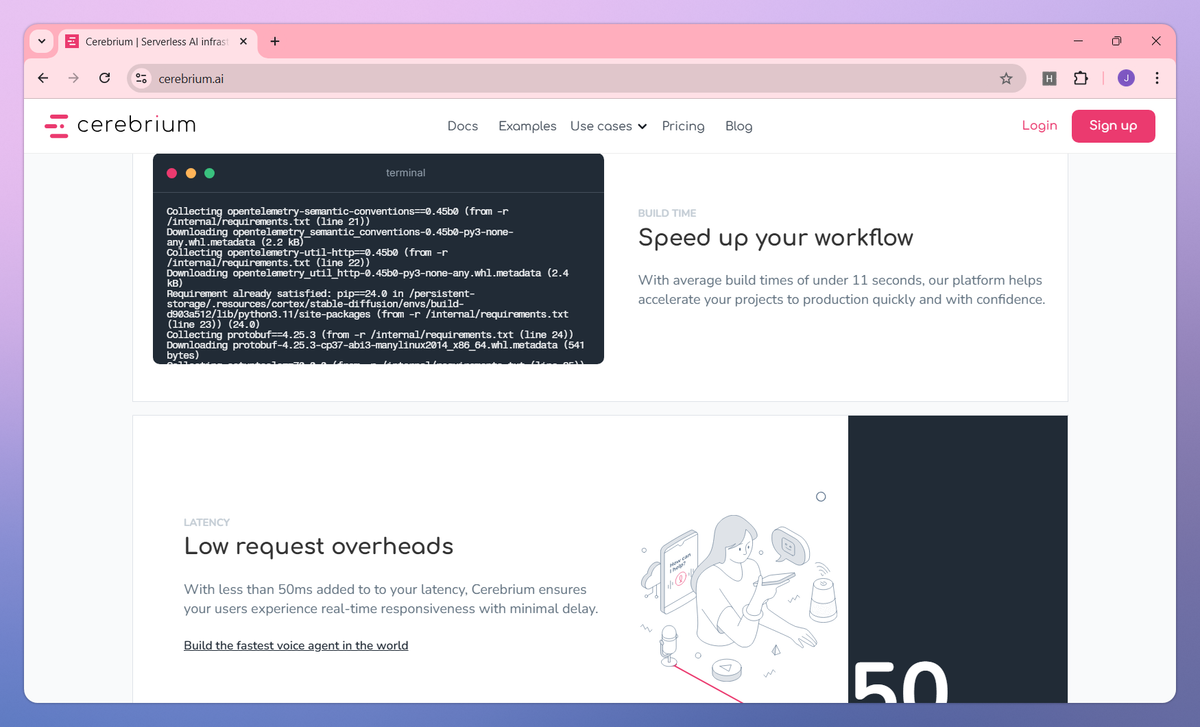
Cerebrium sets itself apart with an extensive selection of GPU hardware options including H100s and A100s, allowing machine learning engineers to match specific workloads with ideal computing resources. The platform's cold start times of under 5 seconds enable data scientists to iterate and deploy models to production with unprecedented speed. Cerebrium's batching capabilities maximize GPU throughput, reducing costs while maintaining low latency for mission-critical AI applications.
Cerebrium Use Cases
- ML model deployment
- Serverless GPU computing
- Real-time ML inference
- ML infrastructure automation
Who uses Cerebrium?
Features and Benefits
'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_1182_27871'%20x1='12.385'%20y1='12.5872'%20x2='48.2299'%20y2='32.1489'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20offset='0.0938117'%20stop-color='%2352EB07'/%3e%3cstop%20offset='0.347535'%20stop-color='%233EF040'/%3e%3cstop%20offset='0.768595'%20stop-color='%2300FFF7'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e) Deploy machine learning models with cold starts under 5 seconds, eliminating long waiting periods and enabling immediate response to user requests. Blazing-Fast Cold Starts
Deploy machine learning models with cold starts under 5 seconds, eliminating long waiting periods and enabling immediate response to user requests. Blazing-Fast Cold Starts - Pay only for the compute resources used down to the millisecond, with no charges for idle time or unused capacity. Pay-Per-Use Pricing
- Access a wide range of GPUs from NVIDIA H100s to A100s, matching the right hardware to specific workload requirements. Advanced GPU Selection
- Scale from 1 to 10,000+ concurrent requests automatically, handling traffic spikes without manual intervention. Automatic Scaling
- Deploy machine learning applications with minimal configuration through an intuitive CLI and dashboard interface. Simple Deployment Process
Cerebrium Pros and Cons
'/%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M16.0466%206.18948C16.3178%206.46068%2016.3178%206.90038%2016.0466%207.17157L8.40771%2014.8105C8.13652%2015.0817%207.69682%2015.0817%207.42562%2014.8105L3.9534%2011.3382C3.6822%2011.067%203.6822%2010.6273%203.9534%2010.3561C4.2246%2010.085%204.66429%2010.085%204.93549%2010.3561L7.91667%2013.3373L15.0645%206.18948C15.3357%205.91828%2015.7754%205.91828%2016.0466%206.18948Z'%20fill='%23343634'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_1569_59'%20x1='0.289288'%20y1='-0.211567'%20x2='31.2845'%20y2='15.6364'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20offset='0.0938117'%20stop-color='%2352EB07'/%3e%3cstop%20offset='0.347535'%20stop-color='%233EF040'/%3e%3cstop%20offset='0.768595'%20stop-color='%2300FFF7'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e) Makes GPU inference setup significantly faster and easier
Makes GPU inference setup significantly faster and easier - Provides cost savings compared to alternative deployment options
- Has a very helpful and responsive customer support team
- Simplifies the deployment process with serverless infrastructure
 User interface needs more intuitive design improvements
User interface needs more intuitive design improvements - Lacks advanced customization options for complex deployments
- Documentation could be more comprehensive
- Monitoring and logging features need enhancement
Pricing
Free Trial- 3 user seats
- Up to 3 deployed apps
- 5 Concurrent GPUs
- Slack & intercom support
- 1 day log retention
- Everything in Hobby plan
- 10 user seats
- 10 deployed apps
- 30 Concurrent GPUs
- 30 day log retention
- Everything in Standard plan
- Unlimited deployed apps
- Unlimited Concurrent GPUs
- Dedicated Slack support
- Unlimited log retention
Cerebrium Alternatives







