Canvas prompting lets you place real products and real people into AI-generated videos with high visual fidelity. This method opens new creative options for e-commerce advertising and product marketing without hiring a camera crew. All you need are a few images — one of your subject and one of your product — plus a clear prompt and a little iteration. Join our AI Automation Community to download the exact prompts and canvas files used in this guide and to practice these steps with other creators.
What is canvas prompting?
Canvas prompting is a simple, visual way to tell a video generation model how to combine multiple elements into a single scene. Instead of asking the model to invent a product or person from scratch, you provide the model with images as anchors: a subject image and a product image. Then you add a small amount of annotation on that canvas — arrows, text, and a concise action prompt — and feed the result into a video model such as Veo 3 via Flow.
Why use this method for e-commerce ads?
- High product fidelity: the model uses your product image as a visual reference, improving accuracy.
- Fast iterations: you can test different creators, angles, and copy without shipping products or booking talent.
- Cost savings: eliminate the need for on-site production for many short ad formats.
- Flexible outputs: mine clips from generated footage and stitch them into multiple ad variants.
What you need before you start
Gather the following resources before you build your first canvas prompt:
- A clear product image. Remove the background if you want the model to composite the product more naturally.
- An image of the subject you want in the ad. This can be a real creator photo or an image generated in Midjourney or another image model.
- An action prompt describing what you want the subject to do and say.
- A canvas editor such as Canva to assemble the inputs and add simple annotations.
- Access to a video generation workflow that supports frames-to-video, such as Flow + Veo 3.
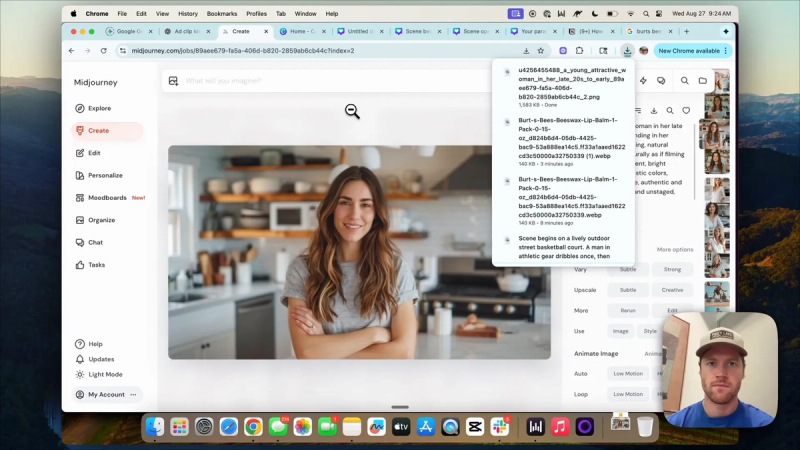
Step 1: Create or select your subject image
If you have a real creator, a single, high-quality head-and-shoulders image works well. If you need to generate a subject, use an image model like Midjourney. The approach here is to meta-prompt: ask ChatGPT to generate a Midjourney prompt that produces a natural, UGC-style influencer image.
Key guidance for the Midjourney prompt:
- Ask for a landscape orientation if the image will be a source frame for video.
- Request natural lighting and minimal cinematic filters. The model performs better with photorealistic references.
- State approximate age, gender, and setting. For example: a woman in her late 20s standing in a bright kitchen, natural expression.
Step 2: Prepare your product image
Download a clean product image from your asset library or from a product page. Remove the background if possible. Smaller items such as lip balm or earbuds need careful scaling and prompt direction to avoid appearing oversized in the final video.
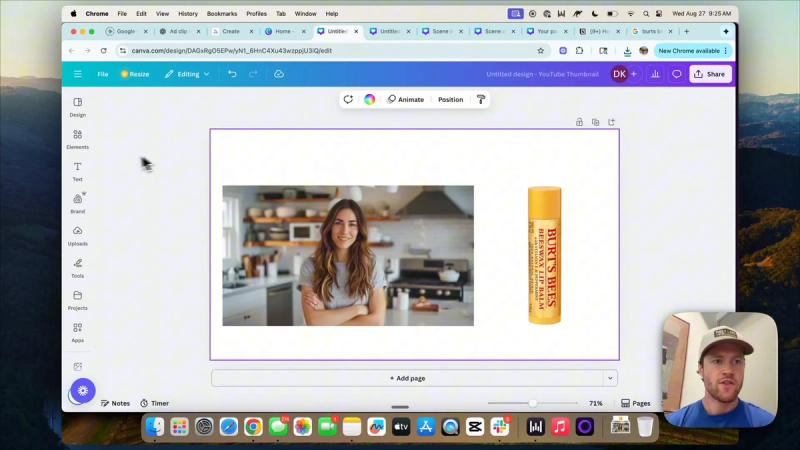
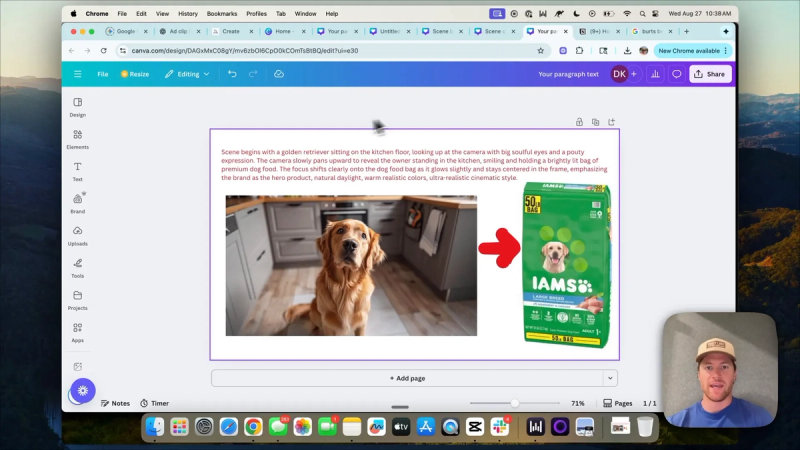
Step 3: Build the canvas in Canva
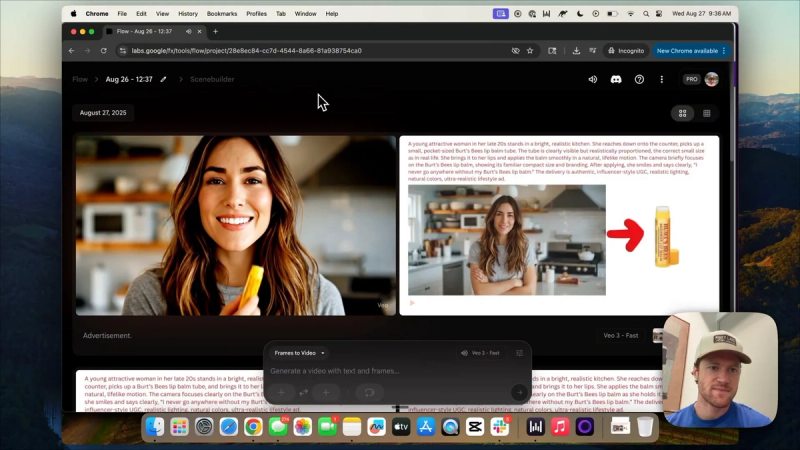
Open a new canvas that matches the video aspect ratio you want. Place the subject image and the product image on the canvas. Use simple drawing tools to annotate the canvas. Two annotations are most useful:
- An arrow indicating which product to focus on or where the model should move the product into the subject's hand.
- Text that contains the action prompt you will feed into Veo 3. Keep this text short and visible on the canvas so the model can read your intent.
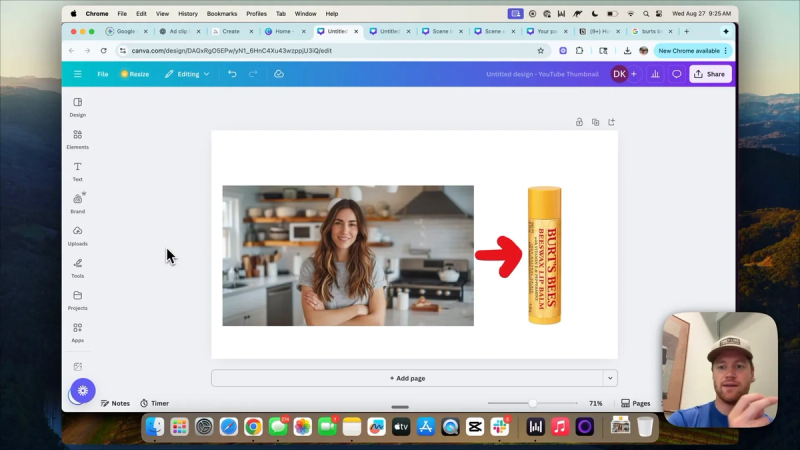
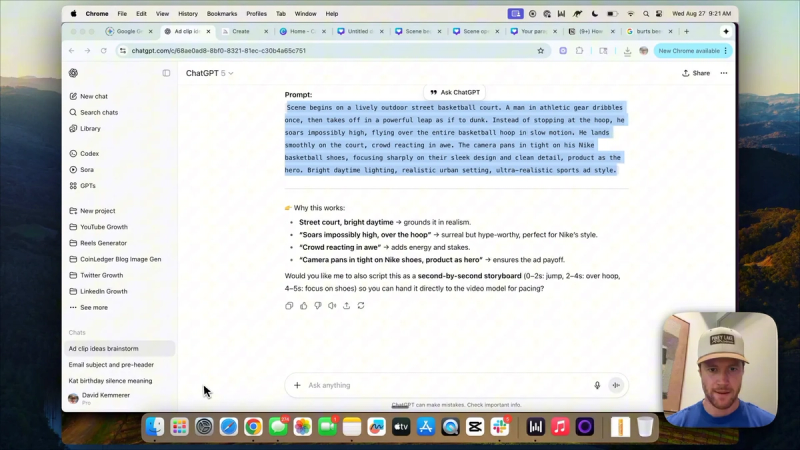
Step 4: Write a targeted video prompt
Now create a prompt for the video model. The best approach here is meta-prompting: ask ChatGPT to produce a Veo 3-ready prompt that captures motion, dialogue, and focus. For example:
A young attractive woman in her late 20s stands in a bright, realistic kitchen. She reaches onto the counter, picks up a Burt's Bees lip balm tube, brings it to her lips, applies it, and smiles. She says, "I never go anywhere without my Burt's Bees lip balm." Make the movements fully lifelike. This is an advertisement focused on the Burt's Bees tube.
Place that text on the canvas in readable color and size. You can also add a short title field when you upload the canvas into Flow, but including the full action on the canvas tends to improve alignment in many cases.
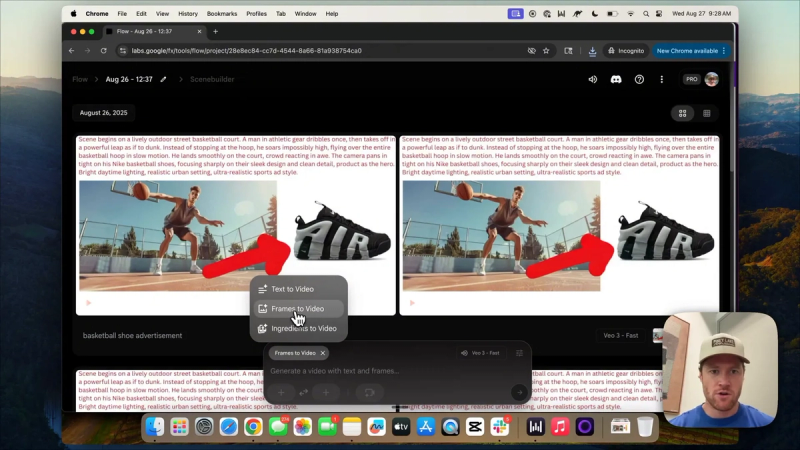
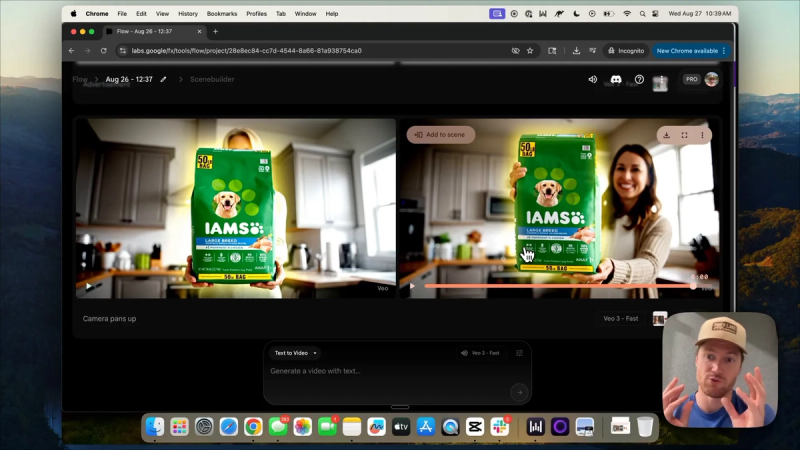
Step 5: Generate video in Flow using Veo 3
In Flow, choose the frames-to-video option and upload your canvas. Add a short label like "lip balm advertisement" to the frame. Select the Veo 3 model and a speed setting. Start a generation run and let the model produce multiple versions. Expect variation across outputs.
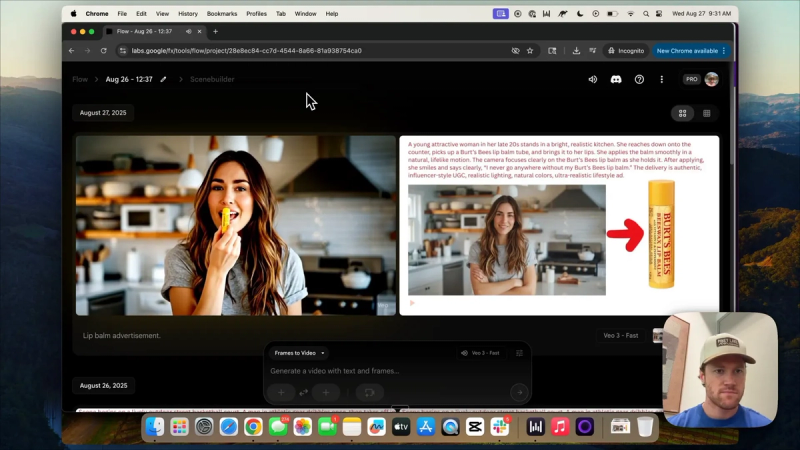
Step 6: Iterate to improve product fidelity
Products, especially small items, can appear the wrong size or unrelated to the subject in early outputs. Treat the generation process like a search. Try these adjustments when fidelity is off:
- Swap product images. A different angle or a background-removed file can help the model place the object better.
- Edit the prompt to specify relative size. For instance, add: "The lip balm tube should appear approximately 1.5 inches tall when held by the subject."
- Reduce the annotation text size and adjust arrow placement to emphasize the product's intended position.
- Regenerate multiple times. Each run is a stochastic attempt; more samples increase the chance of a capture you can use.
Step 7: Mine and stitch footage
Once you have generated multiple clips, treat them as raw footage. Typical editing steps include:
- Cut to the best moment where the subject speaks or interacts with the product. Short UGC ad clips often run 6 to 15 seconds.
- Grab a close-up generated frame focused on the product for the second shot.
- Layer captions, a logo, and music in your editing software. Replace or mute model-generated music if it does not match your ad tone.
For example, you might cut to the line "I never go anywhere without my Burt's Bees lip balm," then cut to a tight product shot for a 1–2 second brand close-up before ending on a call to action.
Practical tips and constraints
- Expect variance: not every generation will be usable. The process is probabilistic.
- Small products need precise prompts and multiple image sources to avoid scale errors.
- Use real creator photos when possible. That reduces the chance of uncanny motion and improves authenticity.
- Annotate carefully. Simple arrows and short text help the model understand which element is the product and how it should move.
- Keep iterations focused. Change only one variable at a time between runs when troubleshooting. That makes cause and effect easier to spot.
Final checklist before publishing
- Do multiple generation runs and save the best clips.
- Confirm product scale and clarity in close-up frames.
- Replace or mute any AI-generated music that conflicts with your brand.
- Caption the spoken line and add a simple call to action at the end of the clip.
- Run an approvals pass with legal and brand stakeholders before launching live campaigns.
Join our AI Automation Mastery community to download the exact prompts and canvas templates used in this guide and to practice these workflows with other builders. The community includes templates for Midjourney prompts, Veo 3 prompts, and annotated canvases that reduce setup time.





