I built a WhatsApp chatbot and AI agent that can handle customer questions about hours, pricing, menus, locations, and appointments in real time. This guide shows the full approach I use: scrape a business website into a concise knowledge base, feed that knowledge into an LLM via n8n, add guardrails to avoid hallucinations, and wire WhatsApp Business API so the agent replies to real customers.
Join our AI Automation Community to download the n8n template used here and get support building this for your business.
What you will learn
- How to scrape and normalize a business website into a single LLM-ready document I call the business encyclopedia and knowledge-base.
- Why I choose a single system-prompt encyclopedia over a multi-service RAG pipeline for many small-business use cases.
- How to connect WhatsApp Business Cloud to n8n and wire incoming messages to an AI agent that consults the encyclopedia before replying.
- How to add memory per phone number so conversations stay isolated per customer.
- Practical configuration tips and production guardrails to reduce errors and bad replies.
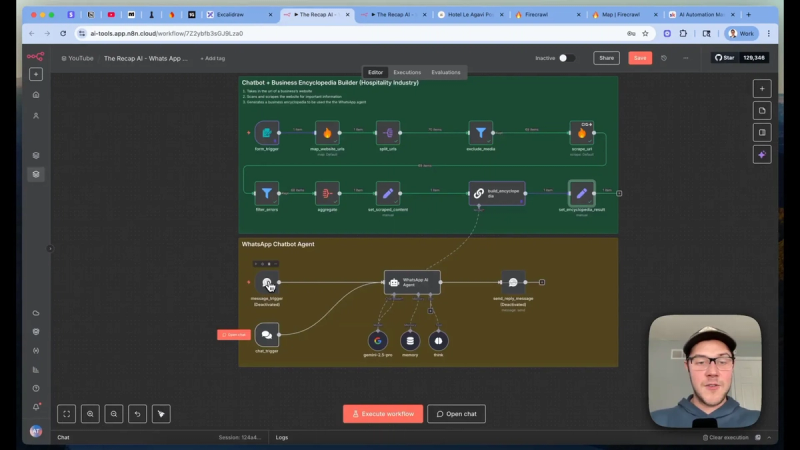
System overview: the four building blocks
The full workflow breaks down into four parts:
- Scrape and extract — take a homepage URL and gather every page of relevant text into markdown.
- Build the business encyclopedia — aggregate and format every page into a deterministic document the agent will consult.
- WhatsApp connection — create WhatsApp Business Cloud credentials and wire triggers and send actions into n8n.
- AI agent and guardrails — set a system prompt, include the encyclopedia, configure memory per phone number, and send replies.
Step 1: Scrape a business website into structured markdown
Start by feeding the business homepage URL into a mapping node that returns every internal URL. I use a community node that integrates with Firecrawl, a scraping API optimized for LLM work. Firecrawl can return text content in markdown format, which keeps token usage low compared to raw HTML.
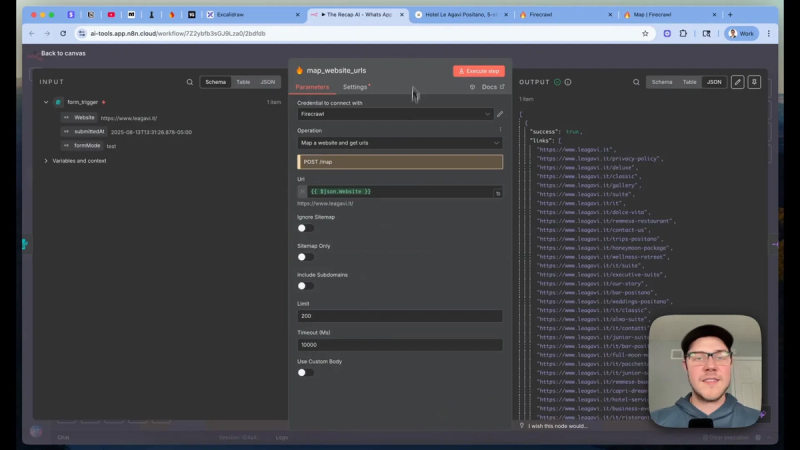
Key choices at this stage:
- Exclude media files such as large galleries to save tokens and keep the encyclopedia focused on text.
- Keep pages that contain policy information, menus, amenity details, and anything that customers ask about.
- For each page, request the markdown output so you get clean, readable text for later prompts.
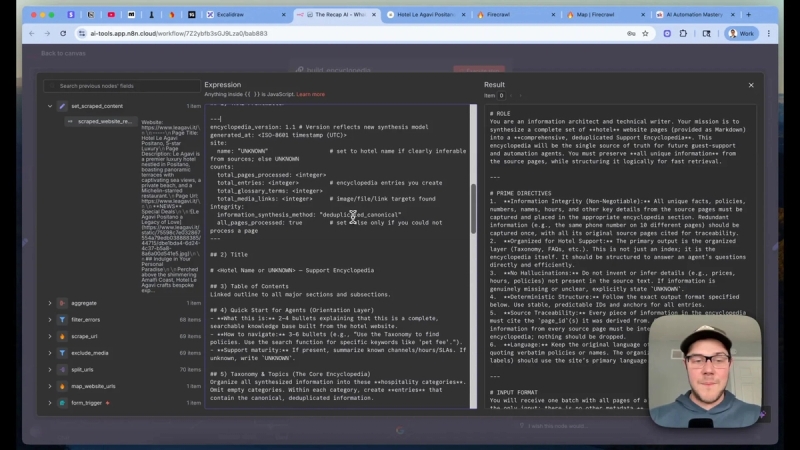
Step 2: Normalize and aggregate into a single encyclopedia
After scraping, run a simple data cleanup pipeline: filter out errors, remove duplicates, and aggregate all page items into one large text field. Add structured metadata for each page such as title, description, and source URL. Then join items using clear separators so the resulting file is both human readable and easy for an LLM to parse.
Why format this into an encyclopedia rather than a raw bundle of pages? A deterministic structure removes ambiguity. The agent will have a consistent format to search and reference when answering questions.
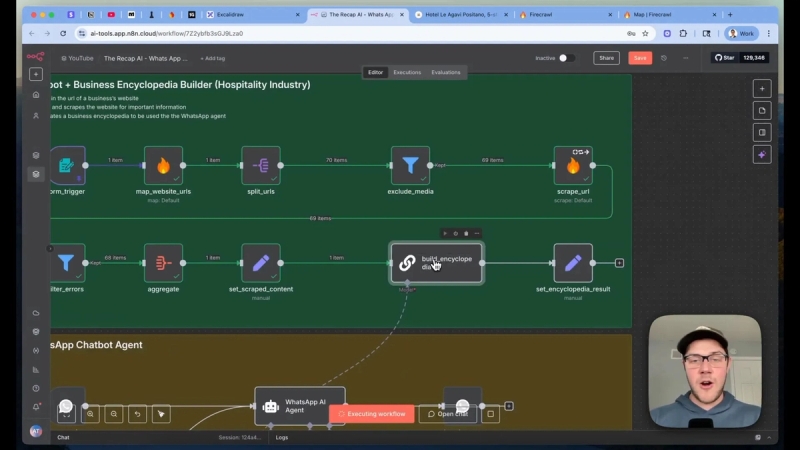
Prompt and output shape
Design your encyclopedia prompt with these prime directives:
- Information integrity — preserve facts exactly as found.
- No hallucinations — avoid inventing details not present in the source content.
- Deterministic structure — same headings and sections across runs.
- Source traceability — include the URL for any fact that might require a direct link back to the page.
When the LLM compiles the encyclopedia, expect a table of contents, clear section headings (amenities, rooms, dining, transfers), and page-level references. Store this output and use it as part of the agent system prompt.
Step 3: Model selection and design decision (Knowledge-base vs RAG)
There is a choice between two main architectures:
- System-prompt encyclopedia — deliver the whole business encyclopedia in the agent’s system prompt so the model can reference it directly.
- RAG pipeline with vector store — chunk content, index in a vector database, retrieve relevant chunks per query, and feed them to the model.
My recommendation for most small-business chatbots is to start with the encyclopedia approach. Reasons:
- Fewer moving parts to manage. You avoid an external vector store, reranker services, and chunking problems.
- Less surface for failures. You rely on a single LLM call instead of multiple networked services.
- If you use a model with a large context window, such as Gemini 2.5 Pro or an equivalent, you can fit a large business encyclopedia without hitting token limits.
RAG has benefits for very large sites or when you need fine-grained chunk retrieval. But RAG increases complexity, and chunking mistakes can lead to hallucinations. Start simple, then add retrieval later when scale demands it.
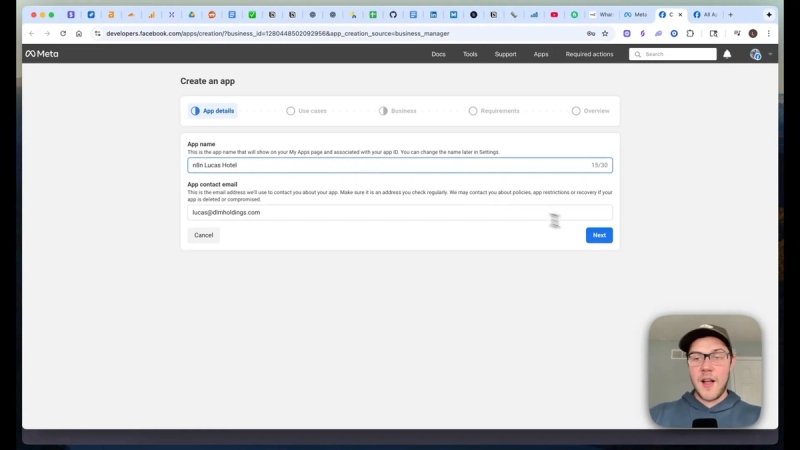
Step 4: Connect WhatsApp Business Cloud to n8n
Next, set up two credential flows in the WhatsApp Business Cloud developer portal: one for receiving hooks and one for sending messages. In short:
- Create an app in the Facebook Developers dashboard and select a Business app type.
- Grab the app ID and app secret for the inbound trigger credential in n8n.
- Generate an access token and obtain the WhatsApp Business Account ID for the send actions credential.
- Whitelist any test numbers you will use during development, or add production numbers before launch.
In n8n, add a WhatsApp Business Cloud trigger node configured with client ID and client secret so the workflow listens for incoming messages. Create a separate credential for the send action to avoid permission issues.
Step 5: Build the WhatsApp AI agent and connect the encyclopedia
Design the agent’s system prompt around a friendly and professional concierge persona with a clear playbook. Key items to include in the system prompt:
- Agent role and tone (concise, courteous, helpful).
- Mandatory step: consult the business encyclopedia before answering.
- When quoting details, include the source URL if available.
- What to do when information is missing: provide a short apology, offer contact or reservation options, and ask a clarifying question if needed.
- Limit response length for WhatsApp readability and format responses into short paragraphs or bullet lists.
Insert the full encyclopedia body below a clear divider in the system prompt. That ensures the LLM always sees configuration rules first and then the reference material it must use.
Step 6: Configure memory per phone number
Memory must be isolated per customer. Use a memory key that combines a fixed prefix and the WhatsApp contact identifier. This prevents one customer’s conversation from leaking into another’s session.
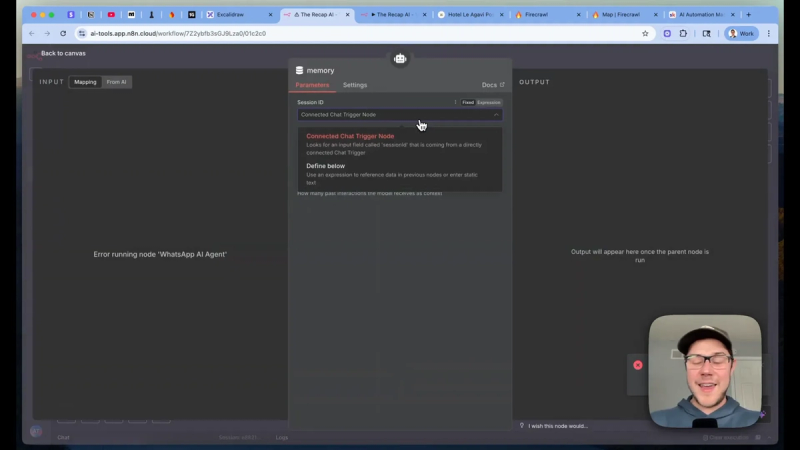
Set a reasonable context window for stored messages, such as the last 20–30 interaction items. This lets the agent reference previous questions and reservations without growing the memory indefinitely.
Step 7: Testing, formatting, and production tips
Run a series of test messages from allowed numbers and inspect full logs in n8n. During testing, watch for:
- Bad request errors from the WhatsApp API when a number is not on the allowlist.
- Formatting issues where the LLM returns long blocks of text. Tune the system prompt to produce shorter, WhatsApp-friendly outputs.
- Hallucinations. If the agent makes up details, tighten the encyclopedia directives and require source references for any factual claim.
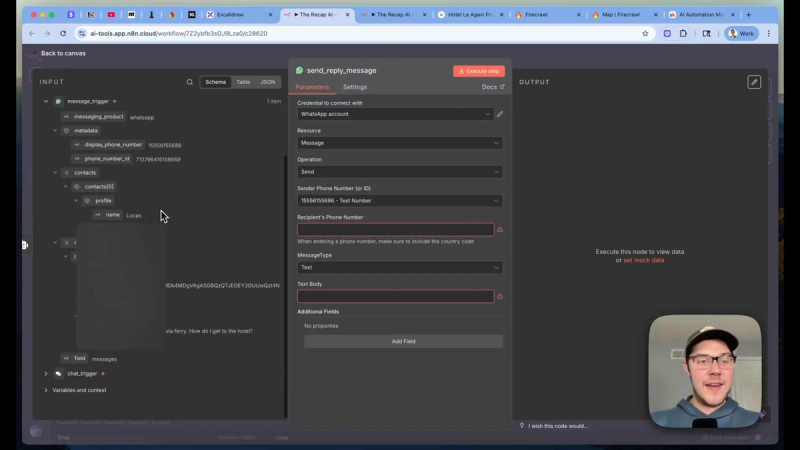
Formatting tips for WhatsApp
- Use short paragraphs and numbered instructions for directions or policies.
- For menus or hours, return bullet lists and link to the source page when relevant.
- Respect WhatsApp character limits and avoid long paragraphs that force scrolling.
Guardrails and error handling
Guardrails reduce risk and build trust with users. Implement these checks:
- If the encyclopedia has conflicting statements, prefer the most recent date or state uncertainty and provide the source link.
- If the agent lacks the exact answer, ask a clarifying question before committing to an action.
- Log every outgoing message and include a fallback human handoff path if the agent cannot answer after two attempts.
Next Steps
Building an AI-powered WhatsApp chatbot in n8n requires a few deliberate choices: scrape and normalize content into a clean encyclopedia, prefer a single-model system prompt when possible, and wire WhatsApp credentials correctly. With memory per phone number and strong prompt directives, you get a reliable assistant that answers customer questions and helps convert inquiries into bookings or sales.
Join AI Automation Mastery to get the free n8n template, the system prompt, and support implementing this workflow for your business.





